【初心者向け】Pandas入門 これだけは押さえておくべき基本操作|データ分析で必須
こんにちは、今回はPythonのライブラリの1つである、Pandasについて紹介したいと思います。

Pandasとは
データ分析用のライブラリで、表形式のデータを効率的に処理するための機能が多く提供されています。
実際のデータ分析作業のうち「データ前処理が8割を占める」とも言われるくらい、データ加工技術はデータ分析者にとって必須スキルであると言えます。また、Pythonでは機械学習用のライブラリもたくさん提供されているため、機械学習を適用する前のデータ加工も、PythonのライブラリであるPandasを使って行われることが多いです。
データソース
今回使用したデータは、以下のKaggleで公開されているポケモンの統計データを加工したものです。
Pokemon with stats | Kaggle
基本操作
Pandasライブラリのインポート
PythonでPandasを使うために、最初にライブラリをインポートします。
import pandas as pd
Pandasは慣習として、「pd」という短縮名でインポートします。
1. データファイルの読み込み(CSV/Excel/TSV)
CSVファイル
CSV形式のデータファイルを読み込む際には、pd.read_csvという関数を使用します。括弧の中には、対象のファイルのパスを記載します。
df = pd.read_csv('../data/Pokemon.csv')
上の例では、プログラムファイルが格納されているフォルダから1つ階層を上がって、「data」というフォルダ内にある「Pokemon.csv」を読み込んでいます。
もし、パスの記述方法についてあまり詳しくない場合は、プログラムファイルと同じフォルダ対象ファイルを置いて、ファイル名をシングルクォーテーション(’)で囲んで記述してもよいです。
df = pd.read_csv('Pokemon.csv')
また、pd.read_csvで読み込んだデータは、「=」の左側の変数に保存することができます。ここの変数名は自由に付けることが出来ます。こちらも慣習として、Pandasの表形式データを表す「データフレーム(DataFrame)」の略で「df」という変数名が使われることが多いです。
Excelファイル
Excel形式のデータを読み込む場合は、pd.read_excelという関数を使用します。使い方はpd.read_csvと同じです。
df = pd.read_excel('../data/Pokemon.xlsx')
TSVファイル
TSV形式のデータを読み込む場合も、CSV形式の場合と同じくpd.read_csv関数を使用します。ただし、オプションとして、「delimiter='\t'」を追加します。
df = pd.read_csv('../data/pokemon.txt', delimiter='\t')
TSV形式のデータは、データがタブで区切られているデータのことです。「delimiter」は区切り文字を意味し、「\t」タブ記号を意味します。
なお、pd.read_csvは、カンマやタブ以外で区切られたデータも読み込むことができ、例えば、「delimiter='XXX'」とすれば、XXXが区切り文字としてみなされます。
2. データの確認
データ全体
Jupyter notebookで、変数名だけ入力して実行すると、データフレームの中身を確認することが出来ます。
df
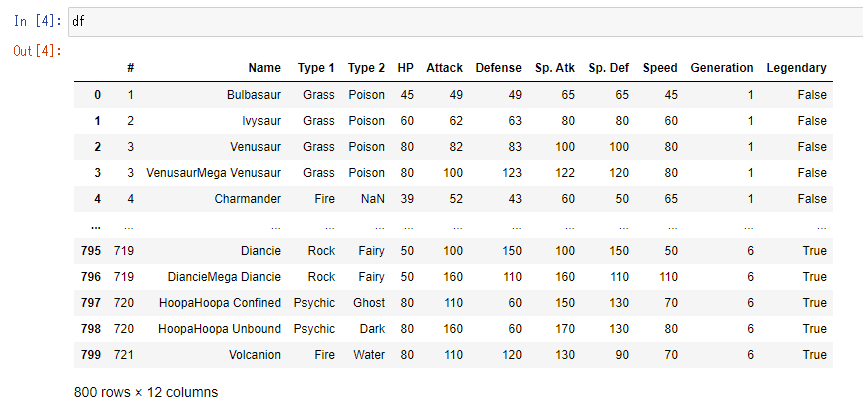
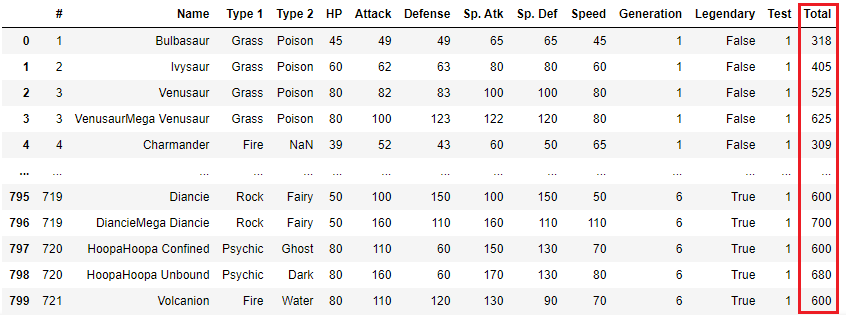
なお、末尾には、行数と列数も表示されています。このデータの場合、800行12列であることがわかります。
列名
「変数名.columns」で列名のリストを表示することが出来ます。
df.columns

特定の列の値
「変数名[’列名’]」で特定の列の値を表示することが出来ます。
df['Name']

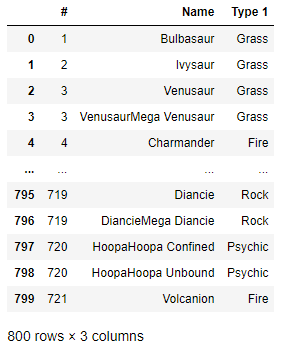
また、複数の列名を指定する場合は、括弧を2重にして指定します。
df[['#','Name','Type 1']]
特定の行の値
「変数名.loc[行インデックス]」で特定の列の値を表示することが出来ます。行インデックスはデフォルトで0から順に整数が割り当てられています。
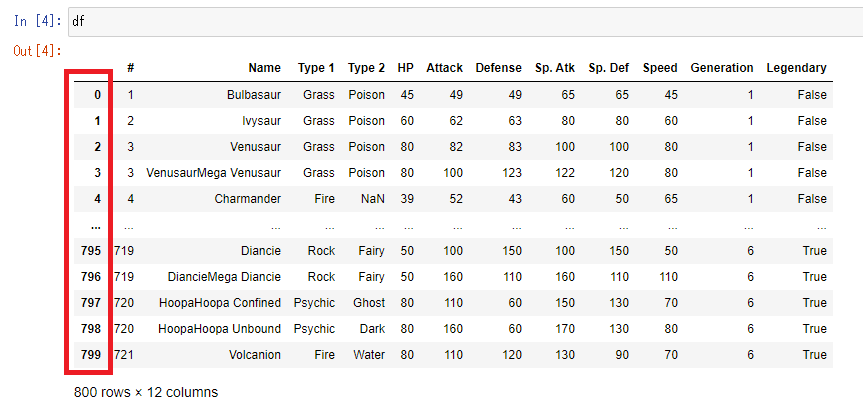
赤で囲んでいる部分が行インデックスです。
インデックスは0始まりなので、2行目を抽出したい場合は1を指定します。
df.loc[1]

また、複数の行を指定する場合は、複数列の指定と同様に括弧を2重にして指定します。
df.loc[[1,4,6]]

3. 行のソート
「変数名.sort_values('列名')」で特定の列をキーとして、行を辞書順または数値順に並べ替えることができます。
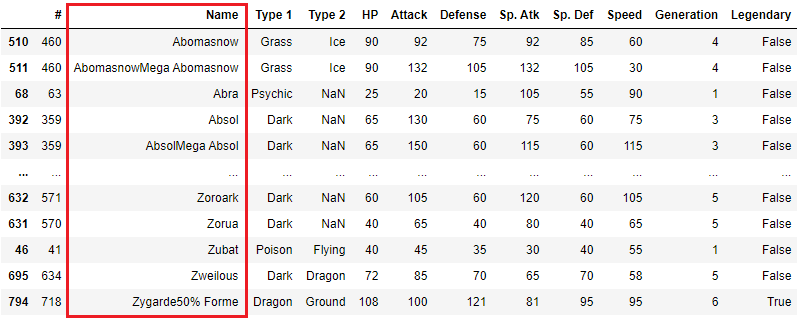
例えば、Name列で並べ替えたい場合は、次の様に実行します。
df.sort_values('Name')
降順に並べ替えたい場合は、「ascending=False」を付けます。
df.sort_values('Name', ascending=False)
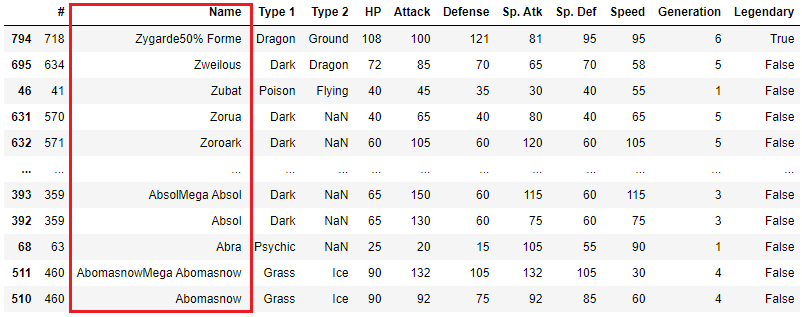
また、[]で囲むことで複数の列をキーとして指定することができます。
df.sort_values(['Type 1', 'HP'])
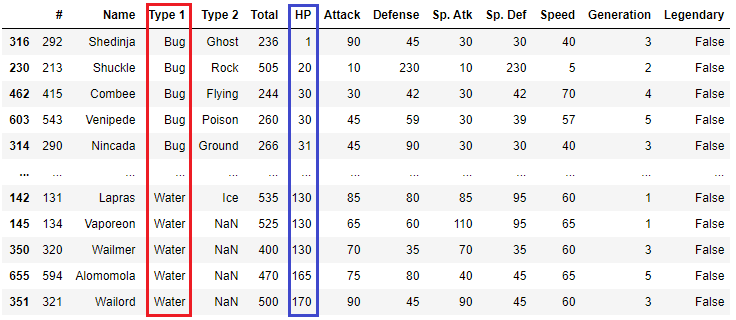
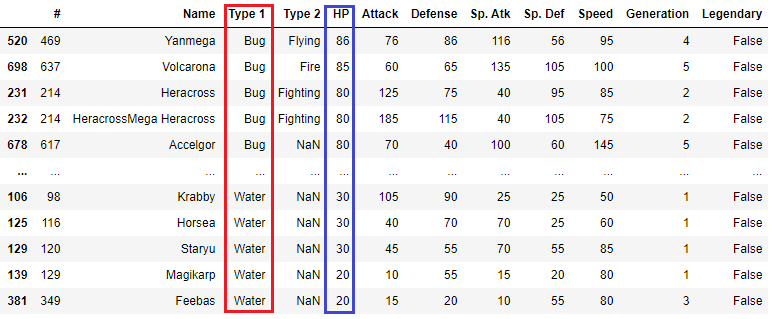
デフォルトだと全て降順になりますが、昇順か降順かを別々に指定することもできます。例えば、Tpye 1を辞書の順に並べ変えて、HPを降順で大きい順に並べ替える場合のコードは以下のとおりです。
df.sort_values(['Type 1', 'HP']) , ascending=[True, False])
4. 列の追加・削除
pandasで読み込んだデータの列を追加することができます。
「変数名['新しい列名'] = 値」とします。
df['Test'] = 1
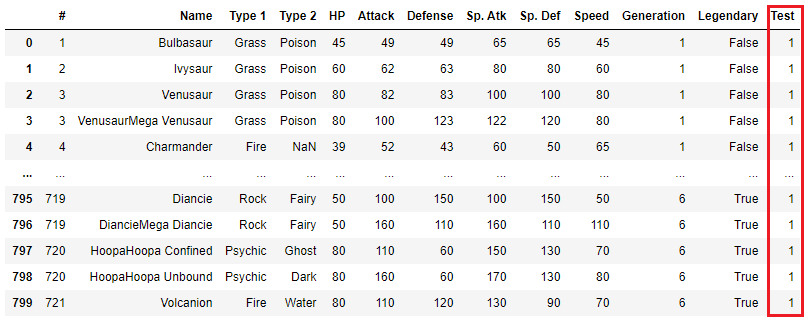
Testという列が追加されて、全ての値が1になっています。
新しい列の値として、それぞれの行で別々の値を設定することもできます。
例えば、各モンスターのHPからSpeedまでを全て足した値を、Totalという列名で追加する場合のコードは以下のとおりです。
df['Total'] = df['HP'] + df['Attack'] + df['Defense'] + df['Sp. Atk'] + df['Sp. Def'] + df['Speed']
列を削除する場合は、「del 変数名['削除する列名']」とします。
先ほど追加したTestという列を削除します。
del df['Test']
5. 列の並べ替え
列の順番を並べ替えることもできます。
ここでは、一番に右側に追加したTotal列を、HP列の前に移動させたいと思います。コードの例は以下のとおりです。
# 現在の列名をリスト形式にして、変数colsに保存 cols = list(df.columns)
# 変数colsの中身を表示 print(cols)
![]()
# 列名のリストをコピーし、表示したい順番に並べ替えて、別の変数cols_newに保存 cols_new = ['#', 'Name', 'Type 1', 'Type 2', 'Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'Legendary']
# 元の変数を上書き保存
df = df[cols_new]

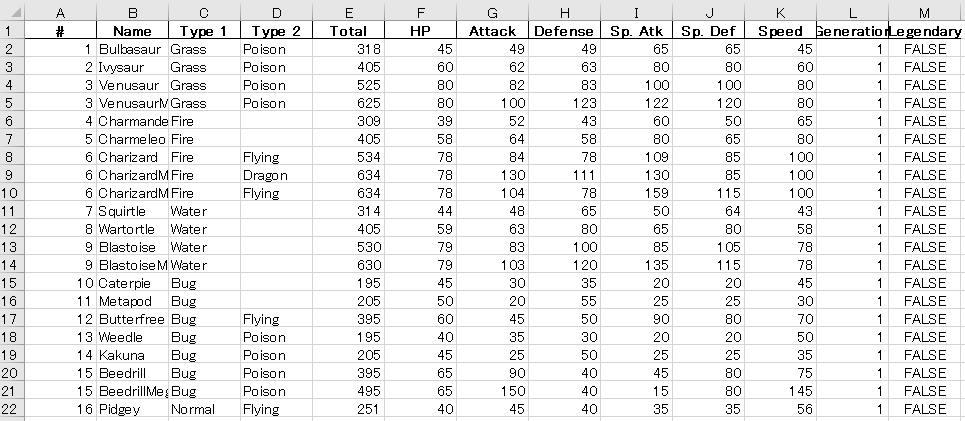
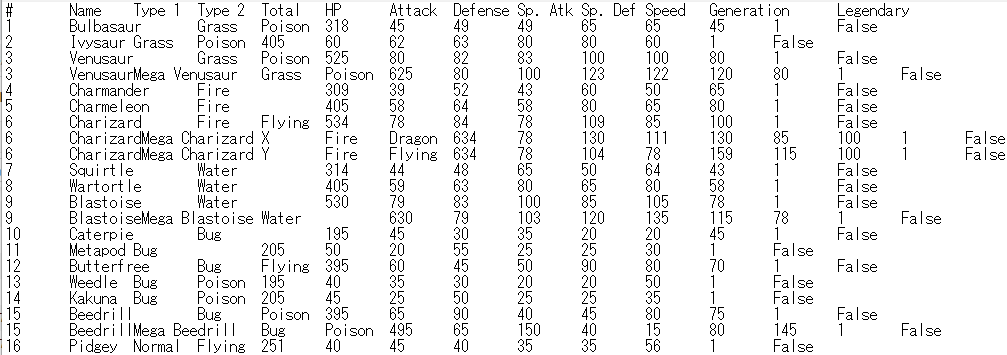
Total列の順番が変更されました。
6. ファイルに保存(CSV/Excel/TSV)
データフレームをファイルに保存することができます。読み込み時と同様に、3種類のファイル形式への出力方法を紹介します。
CSVファイル
データフレームをCSVファイルに保存する場合は、to_csvという関数を使用します。括弧の中には、出力ファイルのパスを記載します。
df.to_csv('../data/Pokemon_v2.csv')
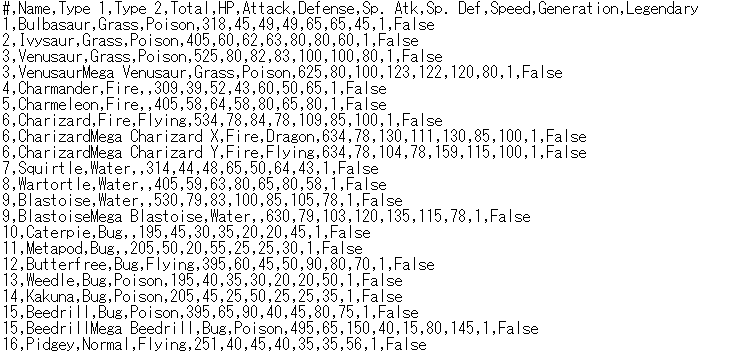
実行すると、CSVファイルが生成されます。
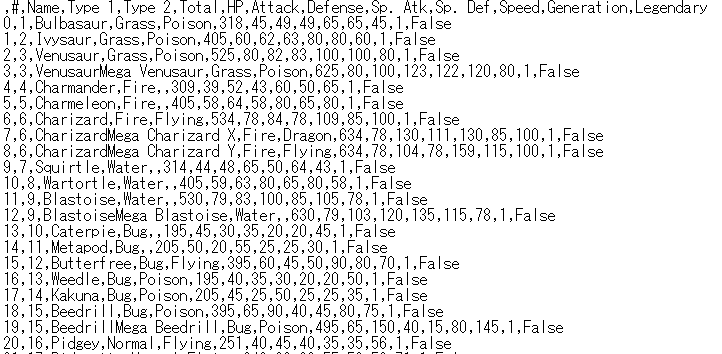
一番左のインデックス番号が不要な場合は、「index=False」を追加して実行します。
df.read_csv('../data/Pokemon_v2.csv', index=False)
まとめ
Pandasの基本操作について紹介しました。今回紹介したとおり、Pandasでは多くの操作について、1行から数行の短いプログラムで書くことができます。そのため、プログラミング初心者でもすぐに使えるようになると思います。
また、今回も、記事の内容を実演した様子を動画にしてアップしています。わかりづらい点があれば、こちらもあわせてご確認ください。
youtu.be
最後まで読んでいただきありがとうございました。