こんにちは。今回は、テキストデータの分析をする際によく用いられるWord Cloudについて紹介します。

Word Cloudは、文章の中に出現した単語を、その出現回数に比例した大きさにして並べたものです。文章データに含まれる情報を抽出し、直感的にわかりやすく可視化することができます。
今回の記事では、Pythonを使ったWord Cloudの作成方法について紹介していきます。
なお、上の図のWord Cloudは、あるPyrhonの参考書のショッピングサイトにおけるレビューコメントを元に生成したものです。
想定環境
Windows8または、Windows10で実行することを想定して、記事を書いています。
0.事前準備
Pythonのセットアップ
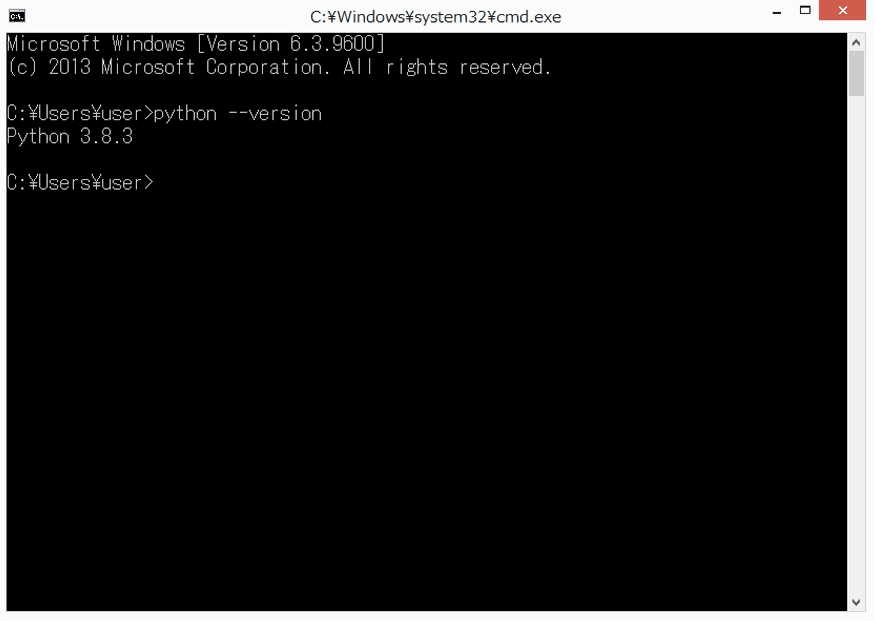
Word Cloudを作成するには、Pythonを使います。もし、Pythonをまだインストールしていない方は、別の記事にしていますので、参考にしてみてください。
dskevin.hatenablog.com
ライブラリのインストール
2つのライブラリをインストールします。
・jannome
janomeを使うと、文章を解析して単語の区切りや品詞を判定して、形態素という細かい単語単位に分割することができます。この分割処理のことを、形態素解析といいます。
例:今日 / は / いい / 天気 / です
名詞 / 助詞 / 形容詞 / 助動詞
・wordcloud
名前のとおり、Word Cloudを描くためのライブラリです。
これらのライブラリは、本記事の執筆時点ではAnacondaで標準インストールされないため、追加インストールが必要になります。コマンドプロンプトを開いて、以下のコマンドを実行するとインストールできます。
pip install janome pip install wordcloud
分析対象ファイルの用意
今回は、より多くの方に使えるようにするため、テキスト形式(.txt)のファイルに書かれた文章を対象に、Word Cloudを描画する方法を紹介します。そのため、例えば、Excelファイル内のテキストを対象にしたい場合は、内容をメモ帳などにコピーして、テキスト形式のファイルに保存します。その際、改行や空行が残っていても、Word Cloudの結果には影響ありませんが、絵文字などの環境依存文字が含まれている場合は、念のため取り除くことをオススメします。
これで事前の準備は完了です。
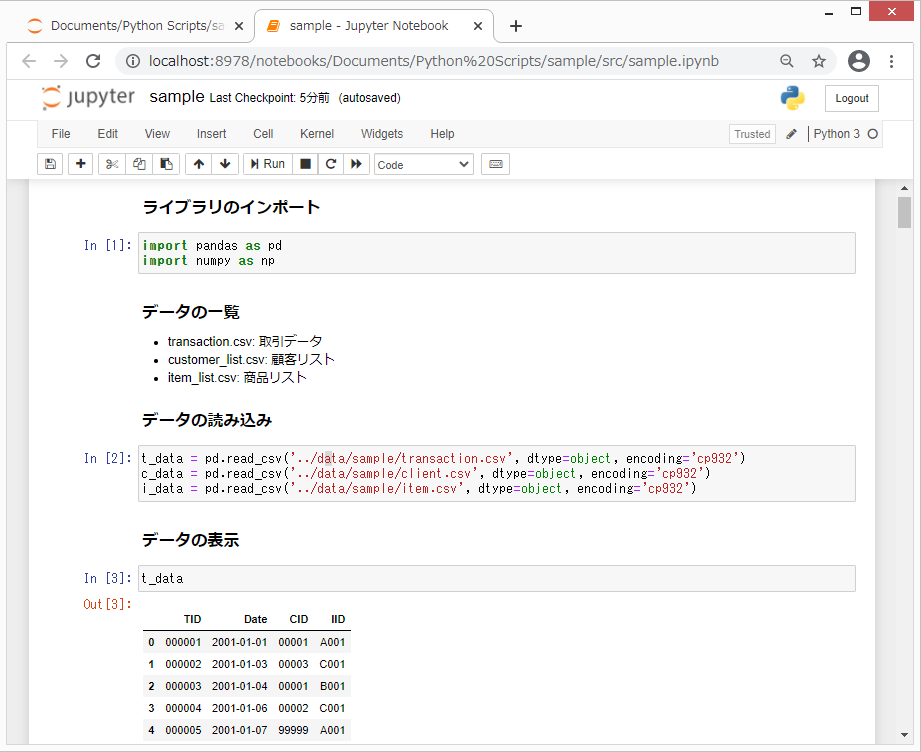
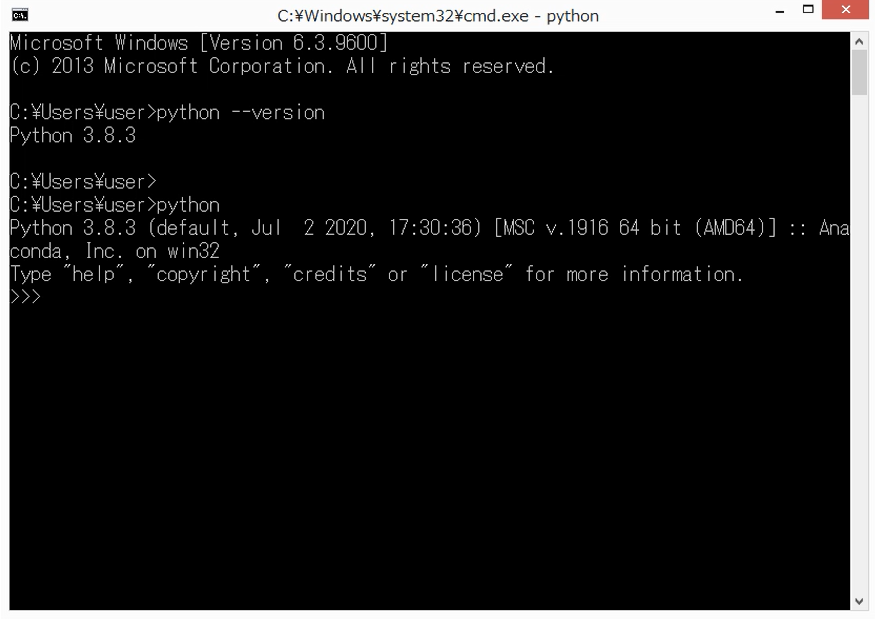
1. Jupyter Notebookの起動
Pythonの実行環境を起動します。ここでは、Jupyter Notebookを使用します。他のPython実行環境でも問題ありません。
コマンドプロンプトから、以下のコマンドを実行します。
jupyter notebook
すると、ブラウザが立ち上がり、Jupyter Notebookが起動します。
Jupyter Notebookの使い方についても、別の記事にしていますので、参考にしてみてください。
dskevin.hatenablog.com
2. Word Cloudの作成
Pythonを実行してWord Couldを作成します。基本的には、コピー&ペーストすれば動くように、プログラムを書いています。
まず、ライブラリをインポートします。
from janome.tokenizer import Tokenizer from wordcloud import WordCloud import matplotlib.pyplot as plt
次に、変数を設定します。この部分は、ご自身の環境に合わせて、書き換えが必要です。
# 対象のテキストファイル target_file = 'review.txt' # 対象ファイルの文字コード ※'shift_jis'または、'utf-8'とします file_encode = 'utf-8' # 日本語文字フォントファイルのパス(MSゴシック以外に変えてもOK) font_file_path = r"C:/WINDOWS/Fonts/msgothic.ttc"
target_fileの部分には、対象のファイルの場所を相対パスや絶対パスで記述することも可能です。パスの記述方法についてあまり詳しくない場合は、プログラムファイルと同じフォルダに対象のテキストファイルを置いて、上記の例のように、ファイル名をシングルクォーテーション(’)で囲んで記述すれば大丈夫です。
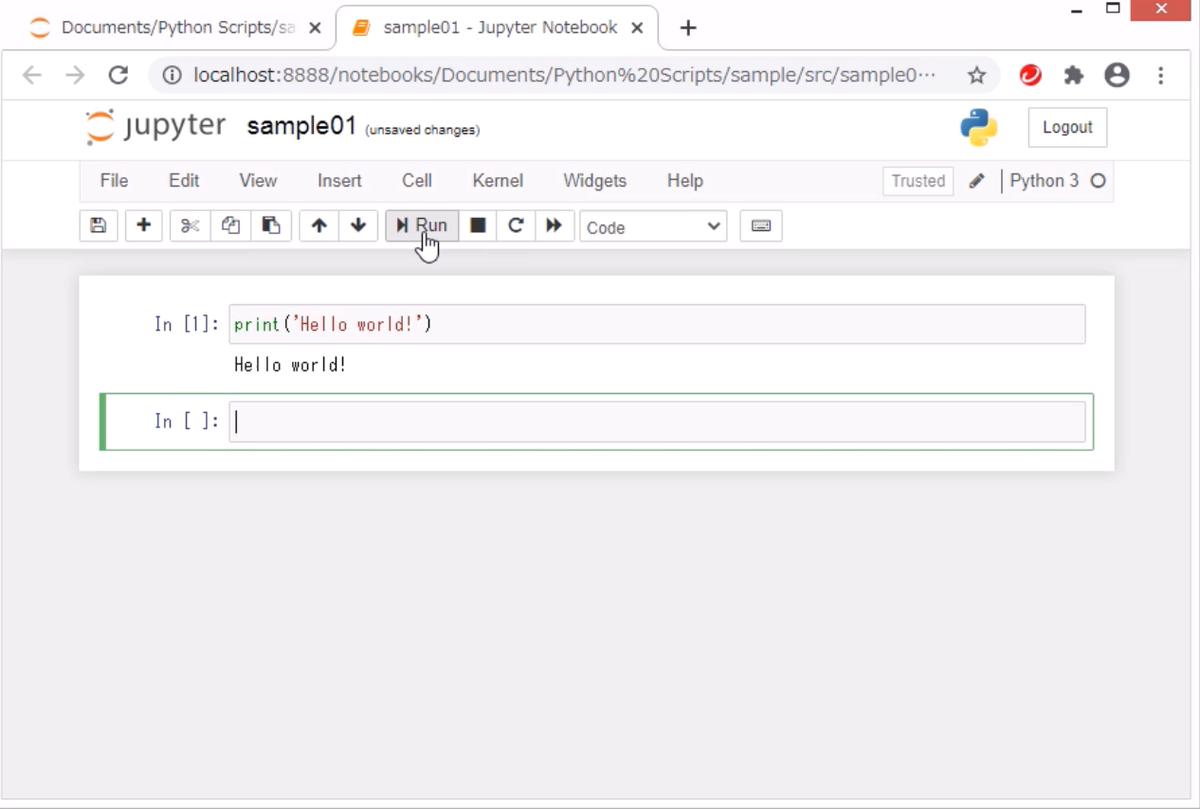
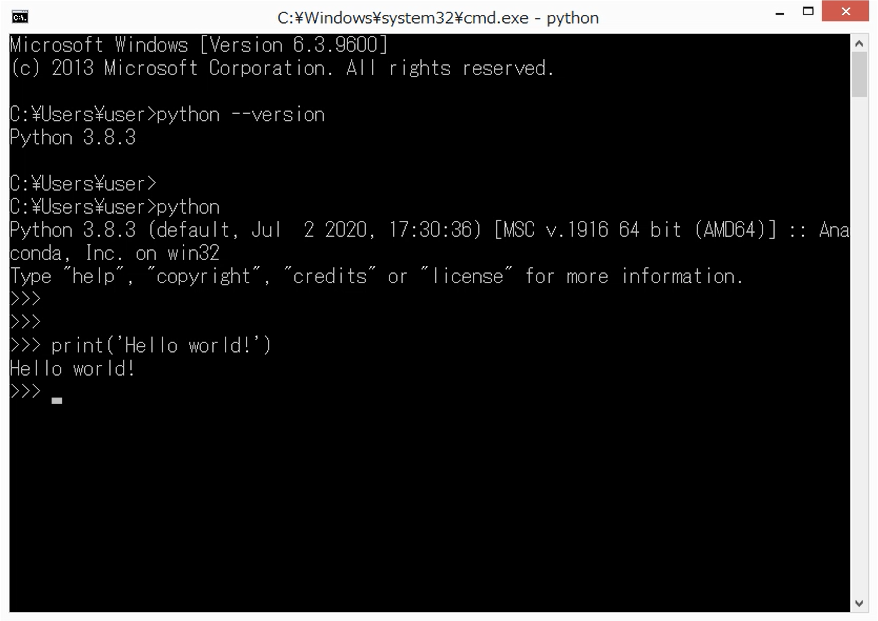
では、いよいよ、Word Couldを作成します。実行コードは以下のとおりです。
# ファイル読み込み f = open(target_file, 'r', encoding=file_encode) target_texts = f.readlines() f.close() # 文章を分解 t = Tokenizer() words = [] for s in target_texts: for token in t.tokenize(s): s_token = token.part_of_speech.split(',') # 一般名詞、自立動詞(「し」等の1文字の動詞は除く)、自立形容詞を抽出 if (s_token[0] == '名詞' and s_token[1] == '一般') \ or (s_token[0] == '動詞' and s_token[1] == '自立' and len(token.surface) >= 2) \ or (s_token[0] == '形容詞' and s_token[1] == '自立'): words.append(token.surface) # Word Cloudの作成 words_space = ' '.join(map(str, words)) wc = WordCloud(background_color="white", font_path=font_file_path, width=500, height=300) wc.generate(words_space) plt.figure(figsize=(15, 9)) plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False, length=0) plt.imshow(wc)
これでWord Cloudが表示されると思います。
なお、Word Cloudは、同じデータを対象に実行しても、毎回、配置や配色が異なった結果が表示されます。そのため、気に入った配置・配色のものが表示されたら、画像を保存するようにしましょう。
また、最後に、それぞれの単語の出現回数を確認する方法についても紹介します。Pandasはデータ分析でよく使うライブラリですので、Pandasを使った例としています。ここでは、出現回数上位の15個の単語を表示しています。
import pandas as pd pd.DataFrame([words]).T[0].value_counts().head(15)

詳細な分析や報告をする際には、このような実際の数値も必要になると思いますので、こちらもご活用ください。
Word Cloudの活用
- 大量のテキストデータの要約
Word Coludは、ユーザーレビュー・アンケート・問い合わせ等のテキストデータから、自社の商品やサービスに対するユーザの声を要約する、といったシーンで活用できます。データ量が膨大で、すべての文章に目を通すのが難しい場合にWord Cloudを作成して、多くのユーザに共通するワードや傾向を見つけ出す、といった使い方ができます。
- プレゼンテーションの見栄え
Word Cloudは視覚的に訴えかけることができるため、見栄えの良いプレゼンテーション資料を作る、という使い方もできます。分析結果を報告する際のプレゼンテーション資料にWord Cloudの結果を入れることで、聴講者の注目を集めるという効果が期待できます。

まとめ
Word Cloudを使って、テキストデータを可視化する方法について紹介しました。Word CloudはPythonを使うことで簡単に作成でき、分析作業やプレゼン資料に活用することができます。そのため、テキストデータを扱う際の手法として、自身の引き出しの1つの加えておいて損はないと思います。今回の記事が、少しでも皆様のお役に立てれば幸いです。
ちなみに、今回、以下の参考書のレビューコメントを元にWord Cloudを作成しました。
こちらは、私がデータサイエンティストになりたての頃に初版が出版された本です。当時はPythonのデータ分析に関する本がまだあまり存在しなかったこともあり、こちらを購入してよく参考にしていました。主にデータの処理(加工、整形、集計)についての実践的なテクニックが載っています。文量が多いので最初に一通りざっと眺めて、「Pyrhonでこんなことも出来るんだ」と、頭に入れた上で、後で実際に作業する時に辞書のように使っていました。こちらも参考になれば幸いです。
★追伸★
本記事を投稿後、実際に本記事を見ながら、コードをコピー&ペーストしてWord Cloudを作成する様子を、動画にしてアップロードしています。必要に応じて、こちらもご参照ください。
youtu.be
最後まで読んでいただき、ありがとうございました。