Pythonで動く棒グラフを作成する方法|Bar Chart Race
こんにちは。時系列で動く棒グラフをYoutube等で見かけたことがあると思いますが、先日、私も作成してみました。
youtu.be
Pythonで簡単に作れたので、作成手順を共有したいと思います。
想定環境
Windows8または、Windows10での実行を想定しています。
1. 事前準備
1-1. Pythonのセットアップ
Pythonを実行できる環境を用意します。同様のアニメーショングラフを作成できるWebサービスは複数ありますが、Pythonを使って書くメリットとしては、自分のパソコンで作成できる点です。業務データなど、オンラインにアップロードすることに抵抗がある場合にも、気にせずに作成することが出来ます。
もし、Pythonをまだインストールしていない方は、別の記事にしていますので、参考にしてみてください。
dskevin.hatenablog.com
1-2. FFmpegのインストール
1-2-1. ソフトウェアのダウンロード
以下のサイトにアクセスします。
Release ffmpeg git 2022-02-17 builds · GyanD/codexffmpeg · GitHub
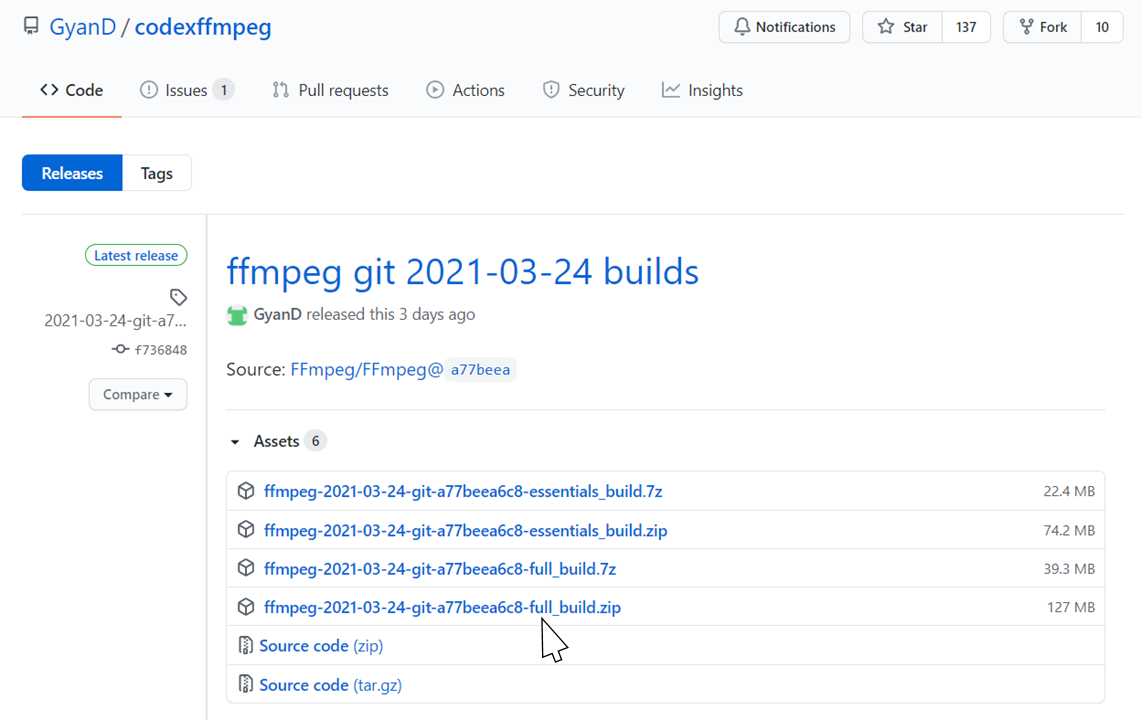
ここで、「ffmpeg-2021-03-24-git-a77beea6c8-full_build.zip」を選択してダウンロードします。ファイル名のバージョンを表す部分は、本記事の作成時点のものになりますので、異なっていても問題ありません。
1-2-2. ファイルの解凍・コピー
ダウンロードが完了したらzipファイルを解凍して、解凍したフォルダを「C:\Program Files」配下にコピーします。
このとき、フォルダ名を「ffmpeg」に変更すると良いです。
1-3. ImageMagickのインストール
1-3-1. ソフトウェアのダウンロード
以下のサイトにアクセスします。
ImageMagick – Download

ここで、「ImageMagick-7.0.11-4-portable-Q16-x64.zip」を選択してダウンロードします。先ほど同様、ファイル名のバージョンを表す部分は、本記事の作成時点のものになりますので、異なっていても問題ありません。
1-3-2. ファイルの解凍・コピー
ダウンロードが完了したらzipファイルを解凍して、解凍したフォルダを「C:\Program Files」配下にコピーします。
こちらも、先ほど同様、フォルダ名を「ImageMagick」に変更すると良いです。
1-3-3. Matplotlibの設定ファイルにパスを設定
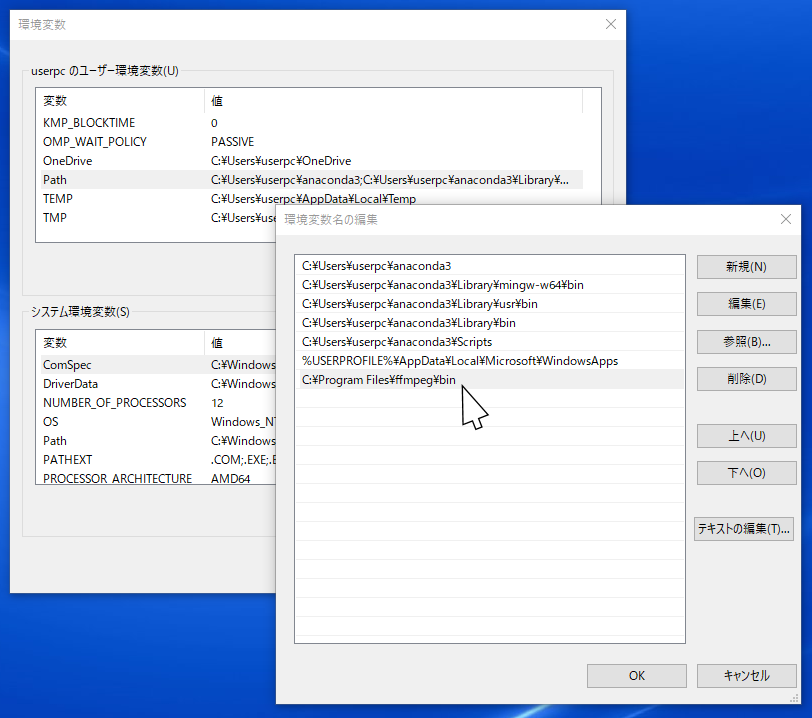
ImageMagickの場合、Windowsの環境変数への設定は不要ですが、代わりにMatplotlibの設定ファイルにパスを設定する必要があります。
設定ファイルの場所:
<Matplotlibのインストールフォルダ>\mpl-data\matplotlibrc
※matplotlibのインストールフォルダ例:
C:\Users\コンピュータ名\anaconda3\Lib\site-packages\matplotlib\
もし場所がわからなければ、以下のPythonプログラムを実行すれば確認できます。
import matplotlib print(matplotlib.matplotlib_fname())
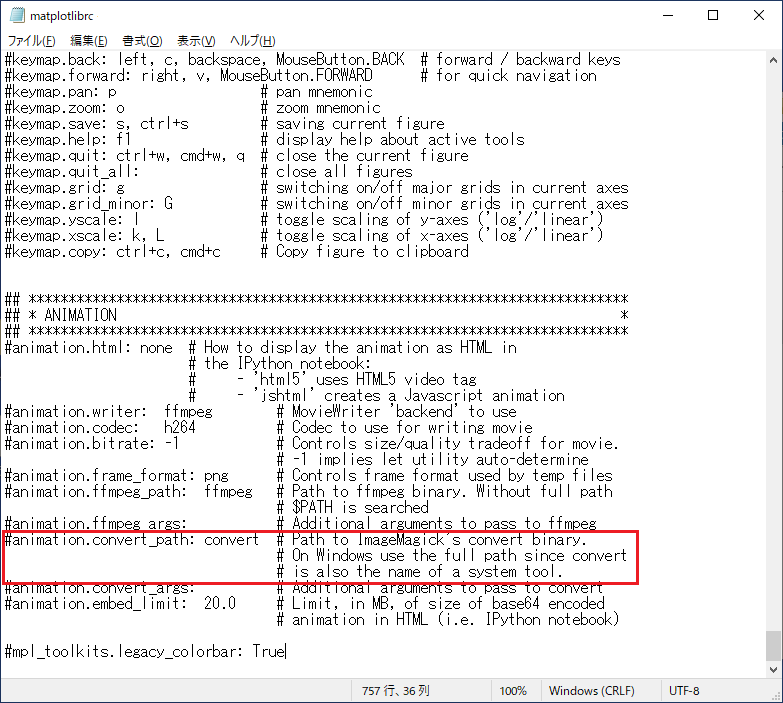
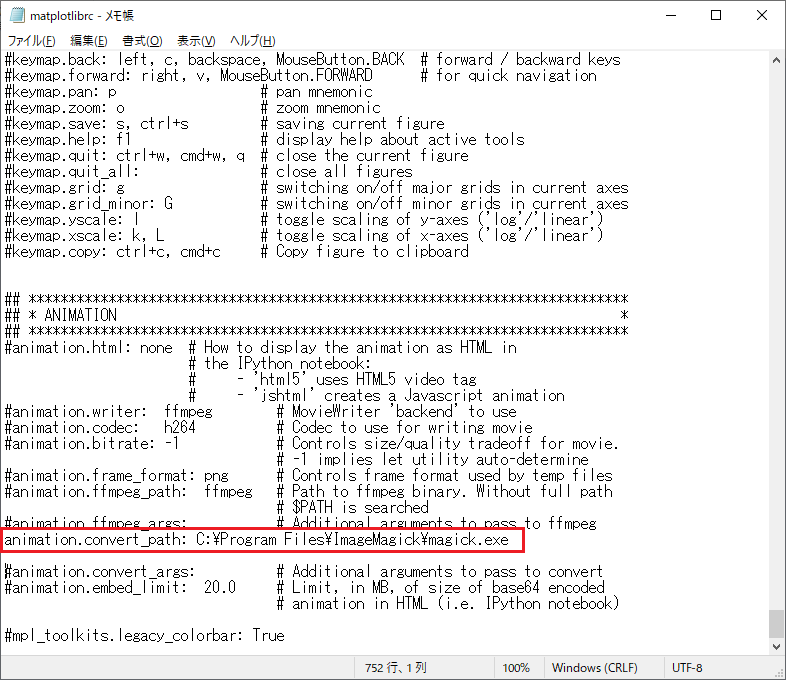
設定ファイルをメモ帳などのエディタで開いて、「animation.convert_path」の部分を以下の内容に書き換えます。
animation.convert_path: C:\Program Files\ImageMagick\magick.exe
変更前:
変更後:
1-4. Pythonのライブラリを追加
「bar_chart_race」というライブラリをインストールします。動く棒グラフは、Bar Chart Raceと呼ばれています。
通常、Pythonのライブラリはpip installコマンドでインストールできますが、ここでは、github上に公開されている最新バージョンをダウンロードしてインストールします。本記事の執筆時点では、bar_chart_raceのバージョン0.2が動く棒グラフをサポートしていますが、pip install でインストールするとバージョンが0.1になってしまうためです。
1-4-1. ファイルのダウンロード
以下のサイトにアクセスして、「Code」から「Download ZIP」を選択します。
GitHub - dexplo/bar_chart_race: Create animated bar chart races in Python with matplotlib
1-4-2. ファイルの解凍
ダウンロードが完了したらzipファイルを解凍します。こちらは、「C:\Program Files」配下へのコピーは不要です。
1-5. データファイルの用意
棒グラフを描画するためのデータを用意します。データは以下の形式になるように加工して、CSVファイルとして保存します。
- それぞれの行は、ある1時点のデータを表します
- 1列目は、日付など時間を表す項目とします
- 2列目以降は、カテゴリごとのデータとします
例:プロ野球の各球団の勝利数の推移データ
| date | Giants | Swallows | Tigers | Carp | Dragons | Baystars |
|---|---|---|---|---|---|---|
| 2020-06-19 | 1 | 0 | 0 | 1 | 1 | 0 |
| 2020-06-20 | 2 | 1 | 0 | 2 | 1 | 0 |
| 2020-06-21 | 3 | 1 | 0 | 2 | 2 | 1 |
| … | … | … | … | … | … | … |
これで事前の準備は完了です。
2. Jupyter Notebookの起動
Pythonの実行環境を起動します。ここでは、Jupyter Notebookを使用します。他のPython実行環境でも問題ありません。
コマンドプロンプトから、以下のコマンドを実行します。
jupyter notebook
すると、ブラウザが立ち上がり、Jupyter Notebookが起動します。
Jupyter Notebookの使い方についても、別の記事にしていますので、参考にしてみてください。
dskevin.hatenablog.com
3. 動く棒グラフの作成
Pythonを実行して作成します。基本的には、コピー&ペーストすれば動くように、プログラムを書いています。
まず、ライブラリをインポートします。
import pandas as pd import bar_chart_race as bcr
次に、先ほど用意した対象のデータファイルを読み込みます。target_fileという変数に、ファイルのパスを記載して実行します。相対パスや絶対パスで記述することが可能ですが、あまり詳しくない場合は、プログラムファイルと同じフォルダに対象のファイルを置いて、ファイル名をシングルクォーテーション(’)で囲んで記述すればよいです。
# 対象のデータファイル target_file = 'target_data.csv' # CSVファイルの読み込み (最初の列をインデクスに指定) df=pd.read_csv(target_file, index_col=0) # データを確認 df.head()
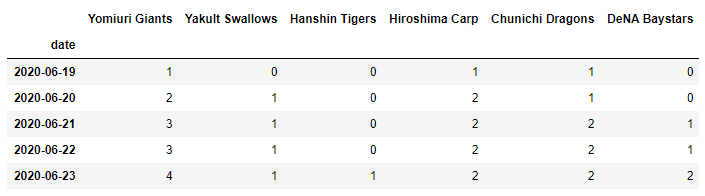
このように表形式のデータが表示されれば、ファイルの読み込みができています。
では、いよいよ、動く棒グラフを作成します。
以下の様に、bcr.bar_chart_raceという関数を実行します。
# bar_chart_raceの作成 bcr.bar_chart_race(df=df, n_bars=len(df.columns))

すると、このように、ノートブック内に動く棒グラフが表示されます。
動画を右クリックすると動画ファイルとして保存することができます。Jupyter Notebook以外の環境で実行する場合は、以下のように、関数の中にfilename='ファイル名'というオプションを追加すると、直接、動画ファイルに出力することができます。
bcr.bar_chart_race(df=df, n_bars=len(df.columns), filename='output.mp4')
また、ここで、棒グラフの見た目をカスタマイズすることができます。今回は、以下の内容を変更しました。
・タイトルを追加
・日付の位置を左下に変更
・バーの幅をやや細く
・バーの色を各球団のチームカラーに変更

Pythonコードは以下のとおりです。
# bar_chart_raceのカスタマイズ bcr.bar_chart_race( df=df ,n_bars=len(df.columns) ,title='NPB Central League 2020' ,period_label={'x': 0.15, 'y': 0.03, 'ha': 'right', 'va': 'center', 'size': 7} ,bar_size=0.7 ,colors=['#f97709', '#98c145', '#ffe201', '#ff0000', '#002569', '#094a8c'] )
他にもパラメータが多数用意されています。詳しくはこちらのページを参照ください。
https://www.dexplo.org/bar_chart_race/
まとめ
FFmpegとImageMagickの設定に少し時間がかかりましたが、Pythonのプログラムは思った以上に簡単でした。動く棒グラフを自分のPCで作成したいという方に、この記事が少しでも役に立てば幸いです。
記事の内容を実演した様子を動画にしてアップしています。文章で分かりづらい点は、こちらの動画もあわせてご確認ください。
youtu.be
動画を作成した際に使用したデータは、以下に公開しています。
セ・リーグ NPB_Central_2020.csv - Google ドライブ
パ・リーグ NPB_Pacific_2020.csv - Google ドライブ
これらは、私が自分でウェブサイトから過去の試合結果を探して入力・作成したデータです。そのため、内容に誤りがあるかもしれませんので、あらかじめご了承ください。
最後まで読んでいただき、ありがとうございました。
職場の同僚たちの34の資質を分析してわかったこと|ストレングスファインダー® 主成分分析
こんにちは。ストレングスファインダー®についてご存じでしょうか。私の所属する部署ではお互いメンバーのことをより深く理解するために、ストレングスファインダー®を活用しています。今回は、職場のメンバーの資質・特徴を分析したところ、面白い結果が得られたので共有したいと思います。
ストレングスファインダー®とは
ストレングスファインダー®は、自分の強みを診断するWebテストです。米国ギャラップ社が開発したもので、200万人以上のインタビュー結果をもとに定義した34の資質の中で、自分が強みとしている資質を知ることができます。177個の質問に答えることで、自分が大切にしている思考や感情を浮き彫りにしていきます。
診断を受けるには、公式サイト*1から申し込みができます。もしくは、ストレングスファインダー®の解説本*2*3に付属のテストコードでも診断することができます。ただし、書籍のテストコードでは、上位5個の資質までしか結果を得られないようです。
ストレングスファインダー®を受けた感想
テストの時間(30分くらい)は、自分の感情と向き合うことが出来る良い機会だと感じました。ただ、質問は日本語で書かれていたのですが、英文を翻訳した日本語の文章によく見られる、ぎこちない表現が多く、質問の意図がわかりづらいものがありました。
診断結果
診断結果として、34の資質を高い順に並べたリストが得られます。(下の表が、私の診断結果です。)それぞれの資質についての解説も付いていますので、自分の強みを理解することができます。
| 1. | 学習欲 | 11. | 達成欲 | 21. | アレンジ | 31. | 社交性 |
|---|---|---|---|---|---|---|---|
| 2. | 分析思考 | 12. | 責任感 | 22. | 収集心 | 32. | 指令性 |
| 3. | 調和性 | 13. | 着想 | 23. | 成長促進 | 33. | 戦略性 |
| 4. | 公平性 | 14. | 未来志向 | 24. | 回復志向 | 34. | 共感性 |
| 5. | 個別化 | 15. | 信念 | 25. | 目標志向 | ||
| 6. | 親密性 | 16. | 自我 | 26. | 活発性 | ||
| 7. | 最上志向 | 17. | 内省 | 27. | 運命思考 | ||
| 8. | 自己確信 | 18. | 規律性 | 28. | コミュニケーション | ||
| 9. | 原点思考 | 19. | 包含 | 29. | ポジティブ | ||
| 10. | 慎重さ | 20. | 適応性 | 30. | 競争性 |
ちなみに、34個の項目の並べる時の組み合わせの総数は、34の階乗で、295232799039604140847618609643520000000通りになります。自分と全く同じ結果になった人は世の中には一人もいないと言っても過言ではないレベルです。
解説を読んだ感想
英語の原文を翻訳した文章が読みづらくて頭に入ってこないです。(二回目笑)
以下、一部を抜粋させていただきます。
- 生まれながらにして、あなたは、自分の仕事からひらめきを得ることを切望することがあるでしょう。
- おそらくあなたは、あたなの系統だった思考スタイルに価値をおいてくれる人にアドバイスを求められるかもしれません。
- あなたは本能的に、状況に応じて、一部の人々と親しく、現実的な会話を交わすかもしれません。
このような感じです。私のモヤッとした気持ちが伝わりましたでしょうか。
とはいえ、過去の200万人以上のインタビュー結果から作られた34個の指標をもとにして、人々のタイプを分類する手法は、データ分析者にとって興味深いため、この結果をもう少し深堀りしていこうと思いました。
同僚の診断結果をあわせて見る
データの作成
同僚の結果を1つのシートにまとめました。それぞれのメンバーの資質を左から順に34個並べたものです。名前は伏せていますが、G列が私です。
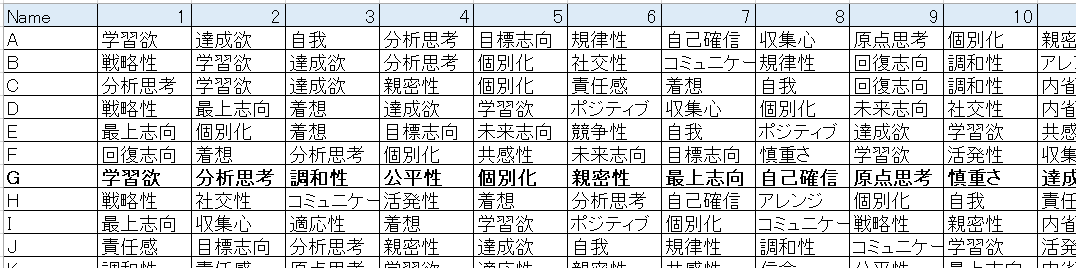
これを数値データに変換して、統計的な手法が使いやすい形にします。
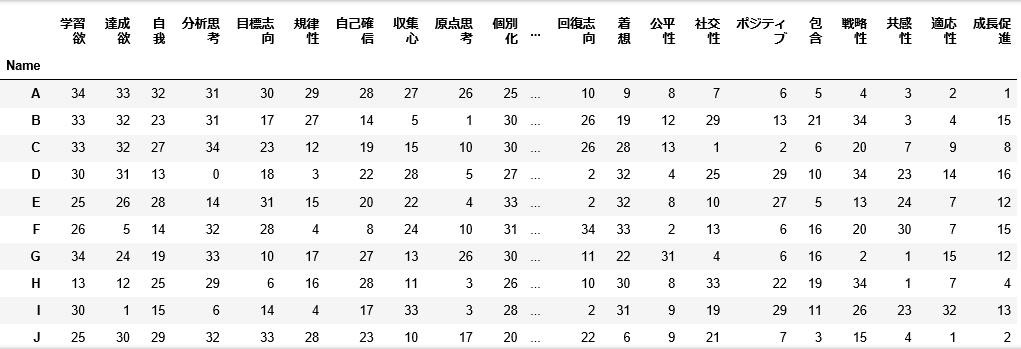
列を資質に固定して、それぞれのメンバーごとに1番強い資質を「34」、2番目に強い資質を「33」、…という様に数字を入れていきます。私(G行)の場合は、学習意欲の列が「34」になっています。
分析手法
今回は、主成分分析という統計学の手法を使います。主成分分析は、多数の項目を、より少ない項目に要約することができる手法です。主成分分析についての詳しい説明は今回は割愛します。
ここでは、34次元のデータを2次元に圧縮することで、縦軸と横軸の2次元平面上に可視化したいと思います。
2次元への圧縮
主成分分析を適用した結果、34個の項目で構成される各メンバーの特徴をなるべく残したまま、2つの項目(主成分)に圧縮するための変換式が算出できました。
PC1 = 0.288×[戦略性] + 0.276×[着想] + 0.235×[最上志向] + …
+ (-0.318)×[分析思考] + (-0.329)×[回復志向] + (-0.336)×[調和性]
PC2 = 0.404×[適応性] + 0.333×[共感性] + 0.328×[成長促進] + …
+ (-0.169)×[活発性] + (-0.223)×[競争性] + (-0.296)×[達成欲]
[項目名]の中には、それぞれのスコア(34~1)が入ります。
例えば、私の場合、G列のそれぞれのスコアを当てはめて、以下の様に計算できます。
PC1 = &0.288×2 + 0.276×22 + 0.235×28 + …
+ (-0.318)×33 + (-0.329)×11 + (-0.336)×32
= -27.836
PC2 = 0.404×15 + 0.333×1 + 0.328×12 + …
+ (-0.169)×9 + (-0.223)×5 + (-0.296)×24
= 7.706
可視化
横軸にPC1のスコア、縦軸にPC2のスコアとすると、全てのメンバーをグラフ上に表示することができます。
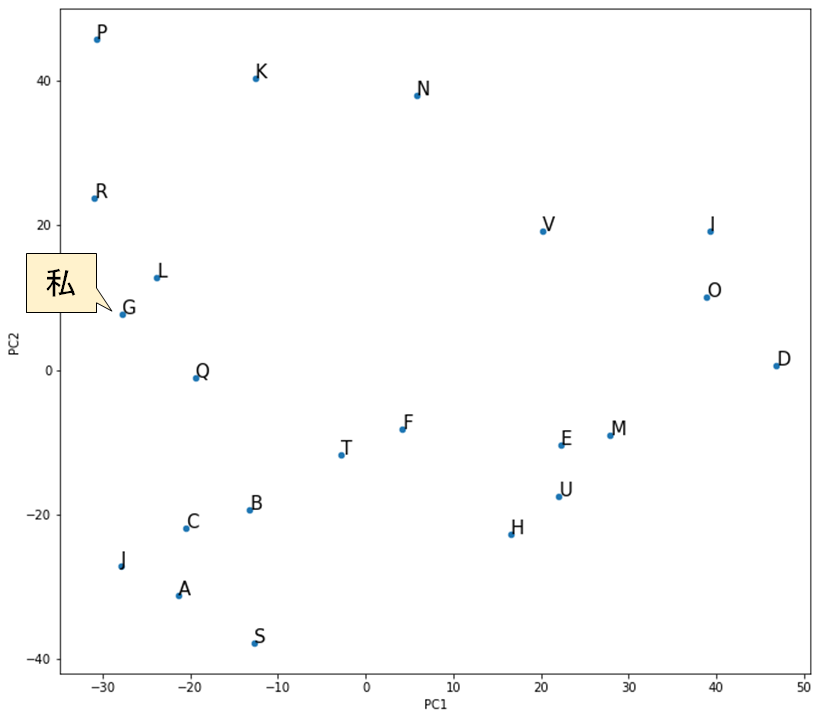
点の位置が近いメンバーは、この部署において他のメンバーと比較して、持っている資質が似ていると言えます。実際に、私の直感と合っていると感じました。
| 同僚 | グラフ上の点の位置 | バックグラウンド | 一緒に仕事をする印象 |
|---|---|---|---|
| L | 近い | 私と同様、前職では官公庁向けのシステム開発を経験 | 仕事を進める上で、気にする観点が共通することが多く、話がスムーズに進むことが多い |
| D | 遠い | 前職では、主にコンサルタントとして施策の立案実施を担当 | 私が思い付かないような発想で、新しいアイディアやアドバイスをもらえる |
リーダーに求められる資質
先ほどのグラフに対して、部署の管理職(アシスタントマネージャー以上)のメンバーに印をつけてみました。
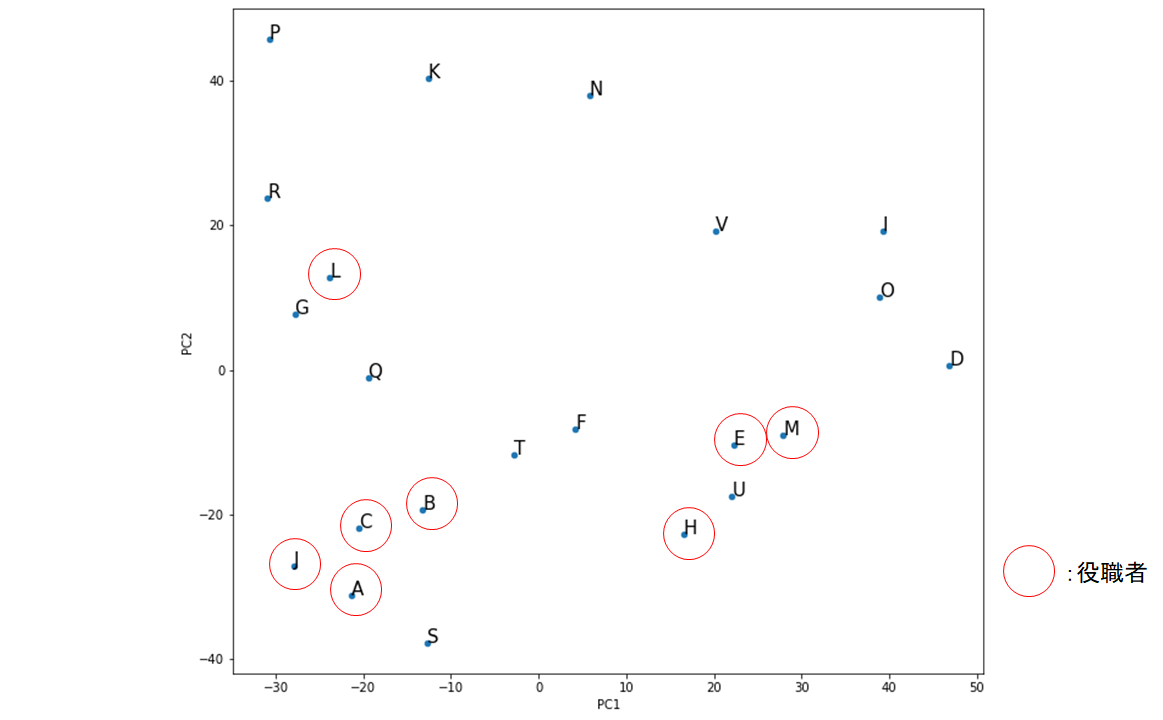
面白いことに、グラフの下半分のエリアに偏っています。Lさんを除いた役職者は全員、PC2の値がマイナスでした。
ここで、改めて、縦軸PC2のスコアを算出するための式を見てみましょう。
PC2 = 0.404×[適応性] + 0.333×[共感性] + 0.328×[成長促進] + …
+ (-0.169)×[活発性] + (-0.223)×[競争性] + (-0.296)×[達成欲]
マイナスの係数がついている資質が強いと、グラフでより下の方に位置することになります。マイナスの係数の絶対値が大きい3つの資質についての説明は次のとおりです。
- 「活発性」の資質が高い人は、アイデアを実行に移すことにより結果をもたらします。単に話すだけではなく、いますぐ実行することを望みます。
- 「競争性」の資質が高い人は、自分の進歩を他の人と比較します。コンテストで勝つために、相当な努力をします。
- 「達成欲」の資質が高い人は、並外れたスタミナがあり、旺盛に仕事に取り組みます。自分が多忙で生産的であることに、大きな満足感を得ます。
これらの項目が、私の所属している部署においてリーダーとして求められる資質であるといえます。今後、これらの項目を強化していくことが、私が現在の部署においてリーダーとして活躍していく上で必要なことだと考えました。
分析手法について
今回の分析のポイントは2点です。
- メンバーの資質を、強い順に34~1で数値化したこと
- 主成分分析で34次元のデータを2次元データに変換したこと
これにより、メンバーの特徴をグラフ上を可視化することができました。
ただ、今回の手法では、全ての資質を1刻みで数値化したため、資質の強弱が直線的になっています。そのため、例えば、一番強い資質が一番弱い資質の34倍の強さを持つことになっています。実際には、資質の強弱は人それぞれ異なります。
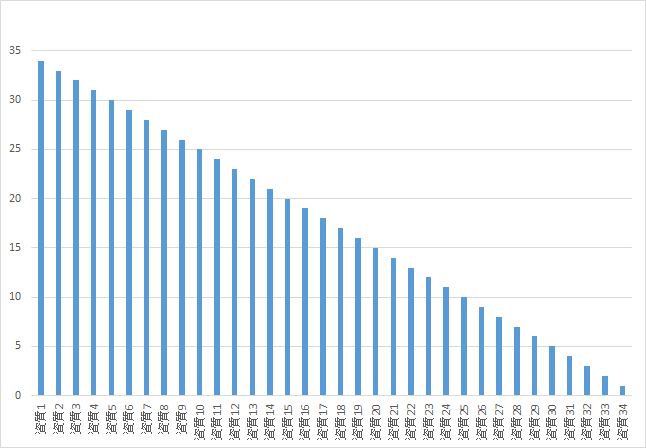
また、34次元のデータを2次元に変換する際に、どうしても、情報量が落ちてしまいます。
そのため、今回はシンプルなモデルで簡易的に分析してみた、という位置づけになる点、ご留意いただけると助かります。
他に、簡単かつ精緻に分析するアイディアがあれば、是非教えていただけると嬉しいです。
まとめ
ストレングスファインダー®は、自分自身の強みや、周囲の人の特徴を理解する上で、便利なツールだと感じました。みなさんも、職場のメンバーでストレングスファインダー®を受診して結果を分析すると、色々な気づきが得られると思いますので、機会があれば是非試してみてください。
ただ、テスト問題および、結果の解説の日本語のわかりづらさは、勿体ないと感じました。もう少し日本人にとって理解しやすい文章になれば、もっと需要は増えると思います。今後のアップデートに期待したいところです!
最後まで読んでいただき、ありがとうございました。
*1:ストレングスファインダー®公式サイト:https://www.gallup.com/cliftonstrengths/ja/
*2:さあ、才能(じぶん)に目覚めよう 新版 ストレングス・ファインダー2.0
に目覚めよう 新版 ストレングス・ファインダー2.0")
*3:ストレングス・リーダーシップ―さあ、リーダーの才能に目覚めよう

exe化したPyrhonプログラムが実行エラーになった場合の対処法|Pyinstaller FileNotFoundError
こんにちは。先日、Pythonプログラムをexeファイル化した時に、なかなかうまくいかず苦戦したので、エラーの内容と対処方法を記事に残しておきます。同様のエラーに遭遇された方の参考になれば幸いです。
exeファイルとは
拡張子が「.exe」になっている実行ファイルのことで、クリックするとプログラムが自動的に実行されます。Windows環境で動作します。
通常、Pythonのプログラムを実行するには、Pythonインストール済のPCを用意する必要があります。しかし、Pythonプログラムをexeファイル化することで、Pythonが未インストールのPCでも、プログラムを実行することが出来ます。

Pythonプログラムをexeファイル化する方法
Pythonプログラムのexeファイルを作成するには、Pyinstallerというライブラリを使用します。最初に、コマンドプロンプトを開いて、以下のコマンドを実行して、Pyinstallerをインストールします。
pip install pyinstaller
次に、exe化したいPythonのプログラムファイル(.py)が存在するフォルダに移動します。
cd 作業フォルダのパス
その後、以下のコマンドを実行します。
pyinstaller プログラムファイル名 -–onefile
「--onefile」というオプションを指定することで、実行ファイルを1つのexeファイルにまとめてくれます。実行後、以下の様なメッセージが表示されれば、exeファイルの作成は完了です。
INFO: Building EXE from EXE-00.toc completed successfully.
遭遇したエラー
出来上がったexeファイルを実行したところ、次のようなエラーが表示されました。
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\userpc\\AppData\\Local\\Temp\\_MEI105442\\wordcloud\\stopwords'
wordcloudライブラリで使用しているstopwordsというファイルが見つからないようです。「--onefile」というオプションを指定しているので、基本的には関連ファイルを含めて1つのexeファイルにまとめてくれるはずですが、漏れてしまったようです。
対処方法(同梱ファイルの追加)
stopwordsは、wordcloudライブラリのインストールフォルダにあります。
「--add-data」オプションを付けて、以下のように実行する必要がありました。
pyinstaller プログラムファイル名 --onefile --add-data wordcloudのインストールフォルダ\stopwords;wordcloud
※wordcloudのインストールフォルダ例:
C:\Users\コンピュータ名\anaconda3\Lib\site-packages\wordcloud\
「--add-data」オプションは、exeファイルに同梱するデータを追加で指定することができ、次のように使用します。
--add-data 元データのパス;取り込み先のパス
今回の場合、元データのパスはファイルのパスをそのまま記入し、取り込み先のパスにはwordcloudとしました。エラーメッセージをみて、stopwordsファイルはwordcloudというフォルダの配下に展開されていることを参考にしました。
遭遇したエラー2
作り直したexeファイルを実行したところ、先ほどのエラーは回避できたのですが、別のエラーが表示されました。
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\userpc\\AppData\\Local\\Temp\\_MEI75162\\janome\\sysdic\\entries_compact0.py'
今度は、janomeライブラリで使用しているファイルが見つからないようです。こちらも、先ほどと同様に、entries_compact0.pyを「--add-data」で追加して再度実行してみました。
ModuleNotFoundError: No module named 'janome.sysdic.entries_compact0_idx'
janomeライブラリのファイルで同梱されないものは、たくさんあるようです…。
対処方法2(同梱フォルダの追加)
wordcloudのstopwordsファイルに加えて、janomeのsysdicをフォルダごと「--add-data」オプションに指定します。
pyinstaller プログラムファイル名 --onefile --add-data wordcloudのインストールフォルダ\stopwords;wordcloud --add-data janomeのインストールフォルダ\sysdic;janome\sysdic
※janomeのインストールフォルダ例:
C:\Users\コンピュータ名\anaconda3\Lib\site-packages\janome\
これでexeファイルが無事に実行できました。
まとめ
今回、wordcloudとjanomeを使う場合以外にも、PyinstallerでNotFoundErrorが出たら、必要なファイルの同梱が漏れている可能性があります。その場合、「--add-data」オプションで、自分で必要なファイルまたは、フォルダを追加してみましょう。将来的には、Pyinstallerの仕様が改善されて「--onfile」オプションで対応できるようになってほしいです。
今回、最初のエラーが出てから、最終的に解決するまでにトータルで3時間以上かかりました。みなさんに同じ苦労を味わってほしくないため、この記事を書きました。少しでもお役に立てば嬉しいです。
最後まで読んでいただき、ありがとうございました。
【テキストデータの分析】Word Cloudの実行ファイルを公開|頻出単語の抽出・可視化用
こんにちは。今回は、「簡単にテキストデータを分析したい」、「Word Cloudを使ってみたいけど、Pythonをインストールしてプログラム実行するのは大変だし、面倒くさい」という方向けに、実行ファイルを用意しました。この実行ファイルを使えば、Word Cloudを簡単に作成できますので、使い方を紹介します。なお、この実行ファイルはWindows環境で動作します。
実行ファイルのアイコン:
テキストデータの可視化(Word Cloud)のイメージ:

1. 実行ファイルのダウンロード
実行ファイルは、Google ドライブ上にzipファイル形式で公開してます。以下のリンクから、zipファイルをダウンロードできます。
wordcloud_kda.zip - Google ドライブ
※ファイルサイズは、400MB以上あります。
ダウンロードの完了後、解凍ソフト等を使用して、zipファイルを展開します。
展開したフォルダには、READMEというフォルダ、exeファイル、sample.txtというサンプルファイルが入っています。また、READMEフォルダの中には、使い方等を記載したREADME.txtが入っています。
wordcloud_kda
├─ README
│ └─ README.txt
├─ sample.txt
└─ wordcloud_kda_vX.X.exe
wordcloud_kda_vX.X.exeの「X.X」の部分は、プログラムの版数が入ります。初版は「1.0」です。
2. 対象ファイルの用意
今回作成した実行ファイルは、テキスト形式(.txt)のファイルに書かれた文章を対象にして、Word Cloudを作成します。そのため、例えば、Excelファイル内のテキストを対象にしたい場合は、内容をメモ帳などにコピーして、テキスト形式のファイルに保存します。
その際、改行や空行が残っていても、Word Cloudの結果には影響ありませんが、絵文字などの環境依存文字が含まれている場合は、念のため取り除くことをオススメします。
3. exeファイルの実行
1. 作業フォルダの作成
デスクトップなど、任意の場所にフォルダを作成します。
2. ファイルの格納
作業フォルダに以下のファイルを格納します。
- Word Cloudの入力にしたい文章が書かれたテキスト形式(.txt)のファイル
- プログラム実行ファイル
プログラムファイルを実行すると、同じフォルダにある全てのテキストファイルを対象に、Word Cloudを作成します。そのため、対象外のテキストファイルは作業フォルダに含めないよう、ご注意ください。
3. 実行
プログラム実行ファイルをダブルクリックします。
初めて実行する場合、Windows OSの設定によって、以下の画面が表示されます。
「詳細情報」をクリックすると、実行ボタンが表示されるので、実行ボタンを押します。
※Google ドライブ上のファイルが改ざんされることは無いと思いますが、もし不安であれば、念のため実行前に、ファイルをウィルスソフトでスキャンしてください。
2回目以降は、実行ファイルをダブルクリックすると、コマンド画面が起動します。
しばらく待つと、プログラムが動作しWord Cloudを自動で作成します。「Enterキーを押して終了します」と表示された後で、Enterキーを押すとコマンド画面が終了します。
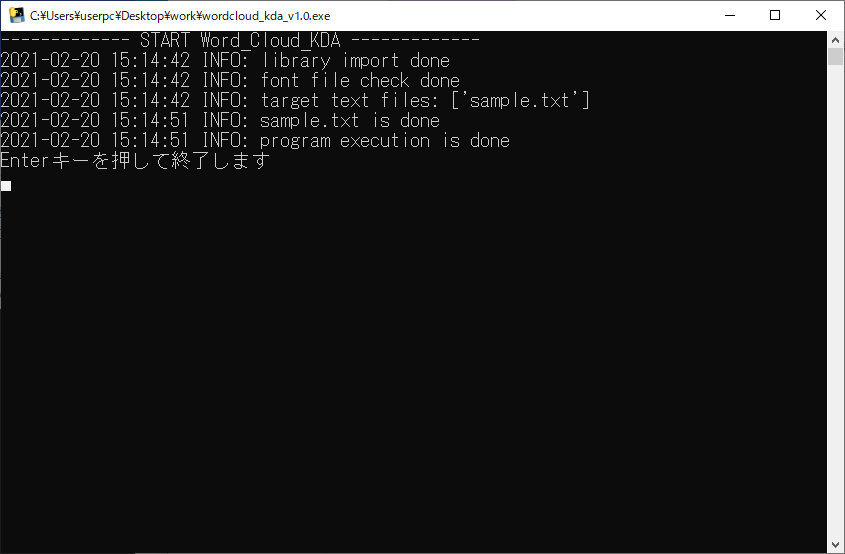
4. 出力ファイルの確認
プログラムを実行して正常に動作した場合、作業フォルダに出力結果のファイルが配置されています。
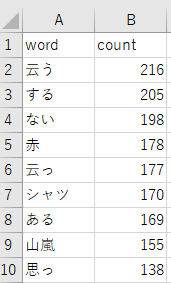
これで作業は完了です。
まとめ
Word Cloud作成用の実行ファイルの使い方について紹介しました。これを使えば、Pythonのインストールとプログラミングは不要で、Word Cloudが作成できます。
前回、コピー&ペーストだけでWord Cloudを作成するという主旨の記事を投稿しましたが、それでも手間だなと感じる方も多いと思い、改めて記事を投稿しました。少しでもお役に立てれば幸いです。
なお、プログラムのソースコードは以下のgithubで公開しています。興味がある方はこちらもご確認ください。
GitHub - kevins-data-analytics/wordcloud_kda
プログラムの更新があれば、google drive上の実行ファイルおよびgithub上のソースコードを更新して公開していきたいと思います。
また、実行ファイルを使ってWord Cloudを作成する様子を、動画にしてアップロードしています。必要に応じて、こちらもご参照ください。
youtu.be
最後まで読んでいただき、ありがとうございました。
【テキストデータの分析】頻出単語の抽出・可視化 Word Cloudの作成|コピペで使えるコード付き
こんにちは。今回は、テキストデータの分析をする際によく用いられるWord Cloudについて紹介します。

Word Cloudは、文章の中に出現した単語を、その出現回数に比例した大きさにして並べたものです。文章データに含まれる情報を抽出し、直感的にわかりやすく可視化することができます。
今回の記事では、Pythonを使ったWord Cloudの作成方法について紹介していきます。
なお、上の図のWord Cloudは、あるPyrhonの参考書のショッピングサイトにおけるレビューコメントを元に生成したものです。
想定環境
Windows8または、Windows10で実行することを想定して、記事を書いています。
0.事前準備
Pythonのセットアップ
Word Cloudを作成するには、Pythonを使います。もし、Pythonをまだインストールしていない方は、別の記事にしていますので、参考にしてみてください。
dskevin.hatenablog.com
ライブラリのインストール
2つのライブラリをインストールします。
・jannome
janomeを使うと、文章を解析して単語の区切りや品詞を判定して、形態素という細かい単語単位に分割することができます。この分割処理のことを、形態素解析といいます。
例:今日 / は / いい / 天気 / です
名詞 / 助詞 / 形容詞 / 助動詞
・wordcloud
名前のとおり、Word Cloudを描くためのライブラリです。
これらのライブラリは、本記事の執筆時点ではAnacondaで標準インストールされないため、追加インストールが必要になります。コマンドプロンプトを開いて、以下のコマンドを実行するとインストールできます。
pip install janome pip install wordcloud
分析対象ファイルの用意
今回は、より多くの方に使えるようにするため、テキスト形式(.txt)のファイルに書かれた文章を対象に、Word Cloudを描画する方法を紹介します。そのため、例えば、Excelファイル内のテキストを対象にしたい場合は、内容をメモ帳などにコピーして、テキスト形式のファイルに保存します。その際、改行や空行が残っていても、Word Cloudの結果には影響ありませんが、絵文字などの環境依存文字が含まれている場合は、念のため取り除くことをオススメします。
これで事前の準備は完了です。
1. Jupyter Notebookの起動
Pythonの実行環境を起動します。ここでは、Jupyter Notebookを使用します。他のPython実行環境でも問題ありません。
コマンドプロンプトから、以下のコマンドを実行します。
jupyter notebook
すると、ブラウザが立ち上がり、Jupyter Notebookが起動します。
Jupyter Notebookの使い方についても、別の記事にしていますので、参考にしてみてください。
dskevin.hatenablog.com
2. Word Cloudの作成
Pythonを実行してWord Couldを作成します。基本的には、コピー&ペーストすれば動くように、プログラムを書いています。
まず、ライブラリをインポートします。
from janome.tokenizer import Tokenizer from wordcloud import WordCloud import matplotlib.pyplot as plt
次に、変数を設定します。この部分は、ご自身の環境に合わせて、書き換えが必要です。
# 対象のテキストファイル target_file = 'review.txt' # 対象ファイルの文字コード ※'shift_jis'または、'utf-8'とします file_encode = 'utf-8' # 日本語文字フォントファイルのパス(MSゴシック以外に変えてもOK) font_file_path = r"C:/WINDOWS/Fonts/msgothic.ttc"
target_fileの部分には、対象のファイルの場所を相対パスや絶対パスで記述することも可能です。パスの記述方法についてあまり詳しくない場合は、プログラムファイルと同じフォルダに対象のテキストファイルを置いて、上記の例のように、ファイル名をシングルクォーテーション(’)で囲んで記述すれば大丈夫です。
では、いよいよ、Word Couldを作成します。実行コードは以下のとおりです。
# ファイル読み込み f = open(target_file, 'r', encoding=file_encode) target_texts = f.readlines() f.close() # 文章を分解 t = Tokenizer() words = [] for s in target_texts: for token in t.tokenize(s): s_token = token.part_of_speech.split(',') # 一般名詞、自立動詞(「し」等の1文字の動詞は除く)、自立形容詞を抽出 if (s_token[0] == '名詞' and s_token[1] == '一般') \ or (s_token[0] == '動詞' and s_token[1] == '自立' and len(token.surface) >= 2) \ or (s_token[0] == '形容詞' and s_token[1] == '自立'): words.append(token.surface) # Word Cloudの作成 words_space = ' '.join(map(str, words)) wc = WordCloud(background_color="white", font_path=font_file_path, width=500, height=300) wc.generate(words_space) plt.figure(figsize=(15, 9)) plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False, length=0) plt.imshow(wc)
これでWord Cloudが表示されると思います。
なお、Word Cloudは、同じデータを対象に実行しても、毎回、配置や配色が異なった結果が表示されます。そのため、気に入った配置・配色のものが表示されたら、画像を保存するようにしましょう。
また、最後に、それぞれの単語の出現回数を確認する方法についても紹介します。Pandasはデータ分析でよく使うライブラリですので、Pandasを使った例としています。ここでは、出現回数上位の15個の単語を表示しています。
import pandas as pd pd.DataFrame([words]).T[0].value_counts().head(15)

詳細な分析や報告をする際には、このような実際の数値も必要になると思いますので、こちらもご活用ください。
Word Cloudの活用
- 大量のテキストデータの要約
Word Coludは、ユーザーレビュー・アンケート・問い合わせ等のテキストデータから、自社の商品やサービスに対するユーザの声を要約する、といったシーンで活用できます。データ量が膨大で、すべての文章に目を通すのが難しい場合にWord Cloudを作成して、多くのユーザに共通するワードや傾向を見つけ出す、といった使い方ができます。
- プレゼンテーションの見栄え
Word Cloudは視覚的に訴えかけることができるため、見栄えの良いプレゼンテーション資料を作る、という使い方もできます。分析結果を報告する際のプレゼンテーション資料にWord Cloudの結果を入れることで、聴講者の注目を集めるという効果が期待できます。

まとめ
Word Cloudを使って、テキストデータを可視化する方法について紹介しました。Word CloudはPythonを使うことで簡単に作成でき、分析作業やプレゼン資料に活用することができます。そのため、テキストデータを扱う際の手法として、自身の引き出しの1つの加えておいて損はないと思います。今回の記事が、少しでも皆様のお役に立てれば幸いです。
ちなみに、今回、以下の参考書のレビューコメントを元にWord Cloudを作成しました。
こちらは、私がデータサイエンティストになりたての頃に初版が出版された本です。当時はPythonのデータ分析に関する本がまだあまり存在しなかったこともあり、こちらを購入してよく参考にしていました。主にデータの処理(加工、整形、集計)についての実践的なテクニックが載っています。文量が多いので最初に一通りざっと眺めて、「Pyrhonでこんなことも出来るんだ」と、頭に入れた上で、後で実際に作業する時に辞書のように使っていました。こちらも参考になれば幸いです。
★追伸★
本記事を投稿後、実際に本記事を見ながら、コードをコピー&ペーストしてWord Cloudを作成する様子を、動画にしてアップロードしています。必要に応じて、こちらもご参照ください。
youtu.be
最後まで読んでいただき、ありがとうございました。
Jupyter Notebook:データサイエンティストを目指す方にオススメのPython実行環境
こんにちは。今回は、多くのデータサイエンティストが実務で使用している、Jupyter Notebookについて紹介します。
Jupyter Notebookとは
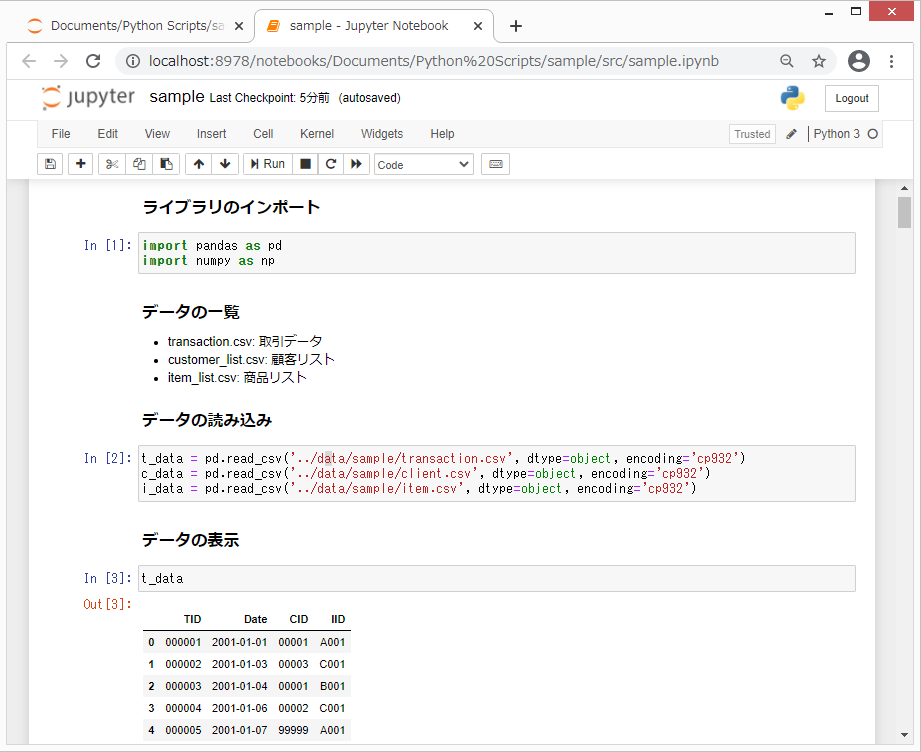
Jupyter Notebookは、ブラウザ上で動作するPythonの実行環境です。下のイメージのように、見やすいデザインの画面にPythonプログラムを記述して、実行することができます。
Pythonの開発ツールは他にもいくつかありますが、Jupyter Notebookが、Python初心者の方やデータサイエンティストを目指す方にオススメです。主な理由として、3つあります。
1. プログラムをセル単位で実行できる
プログラムを少しずつ書いて、実行した結果を確認しながら進められるため、Python初心者の方にも易しい設計になっています。
2. 表やグラフをその場に表示できる
プログラムの実行結果がその場に出るため、データを表やグラフに出力しながら作業することが多い、データ分析者に向いています。
3. プログラムの説明文をセルの外側に書ける
初心者の方が、学習した内容をメモすることに使ったり、データ分析者が、分析作業のプロセスを残すという使い方ができます。
想定環境
以下の環境を想定して、記事を書いています。
- Windows8またはWindows10
- Anaconda(Pythonのディストリビューション)をインストール済
なお、Anacondaのインストール方法については、前回の記事でまとめていますので、よければこちらもご参照ください。
dskevin.hatenablog.com
起動方法
コマンドプロンプトから、以下のコマンドを実行します。
jupyter notebook
すると、ブラウザ上にJupyter Notebookのホーム画面が表示されます。
これで起動できました。
Python実行用の作業フォルダ作成
Jupyter Notebookのホーム画面からは、「Desktop」、「Documents」などのフォルダが見えています。これらは、PC内に実際に存在するフォルダを表しており、Jupyter Notebookから、PC内のデータを参照することができます。
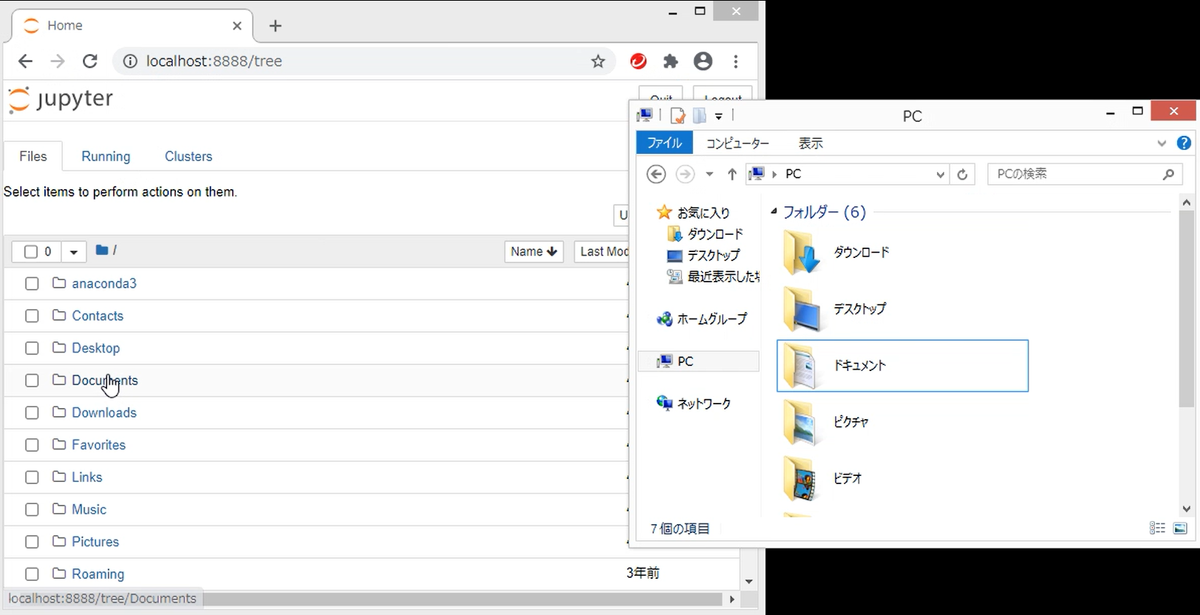
Anadondaをインストールすると、ドキュメントフォルダの下に、「Python Scripts」という空のフォルダが作成されていますので、特にこだわりがなければ、ここに作業フォルダを作成します。
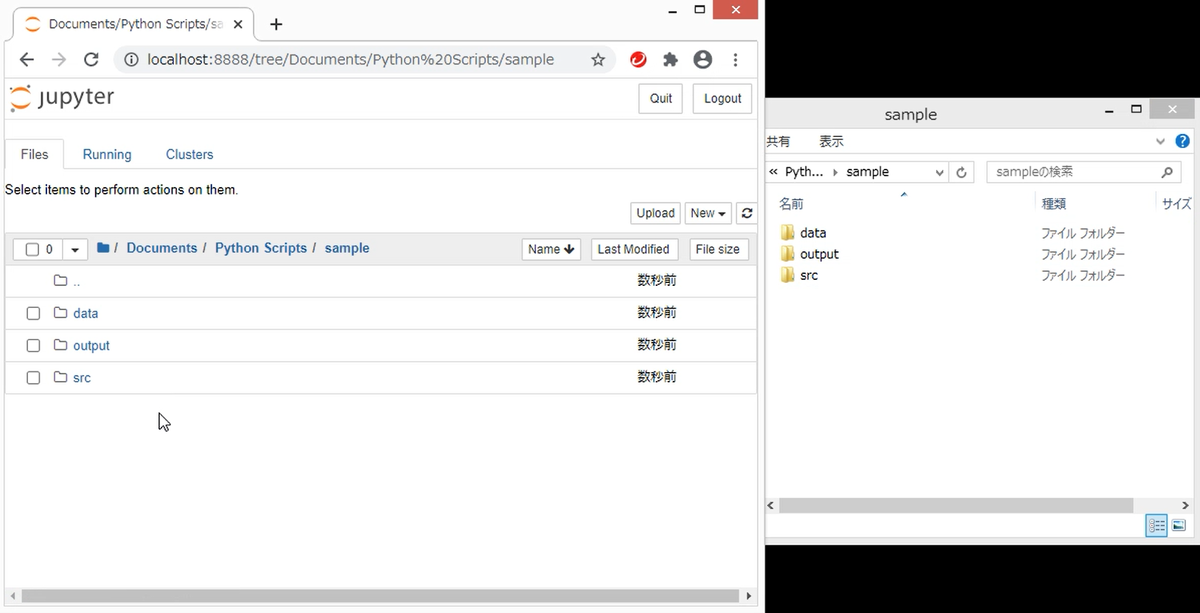
オススメのフォルダ構成は、以下のとおりです。
案件名 →案件ごとにフォルダを作成
├─ data →データを入れる
├─ output →出力結果を入れる
└─ src →Pythonのプログラムを入れる
フォルダを作成すると、Jupyter Notebookの画面にも反映されます。
ノートブックの作成
Jupyter Notebookでは、Pythonプログラムをノートブックという形式で、ファイルに保存できます。同じバージョンのPythonがインストールされた別のPCに、ノートブックのファイルをコピーして、プログラムを実行することもできます。
先ほど作成した作業フォルダに、ノートブックを作成してみましょう。
Jupyter Notebookの画面から、srcフォルダに移動します。右上の「New」ボタンをクリックし、リストの中から「Python 3」を選択します。
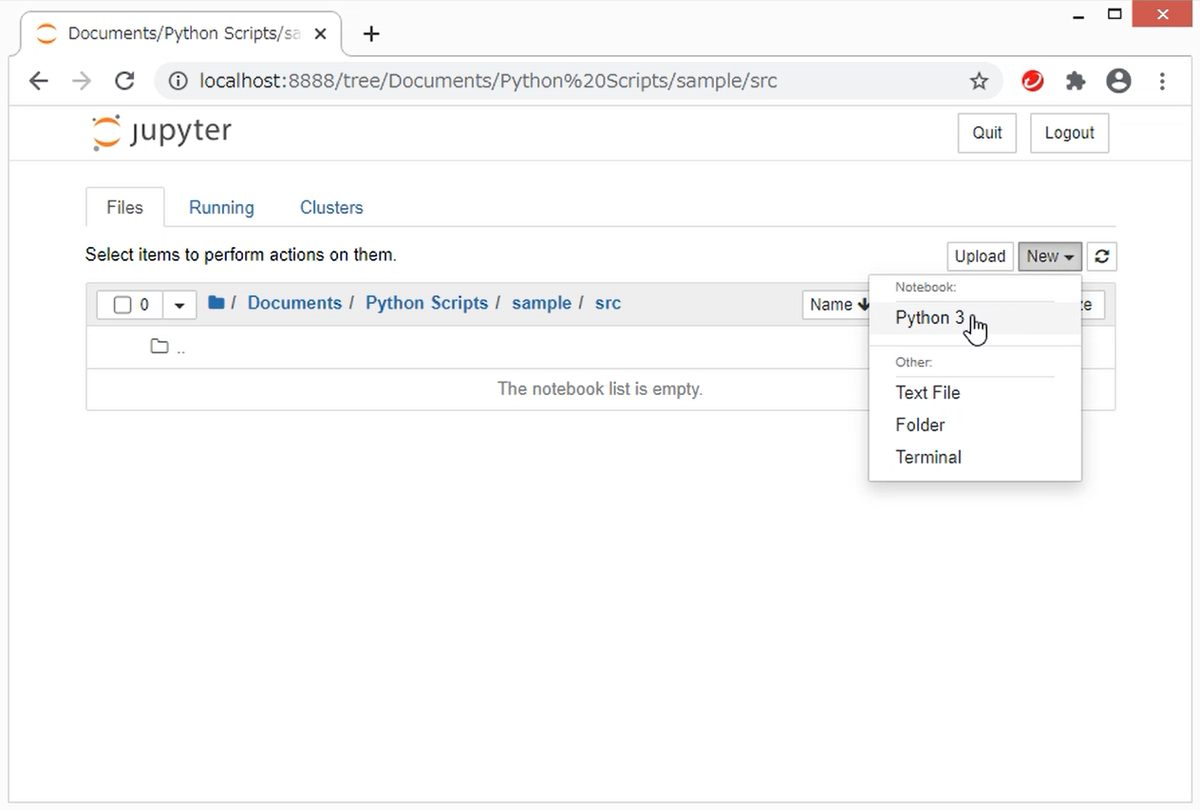
すると、新しいタブが開いて、以下のようなノートブックの画面が表示されます。
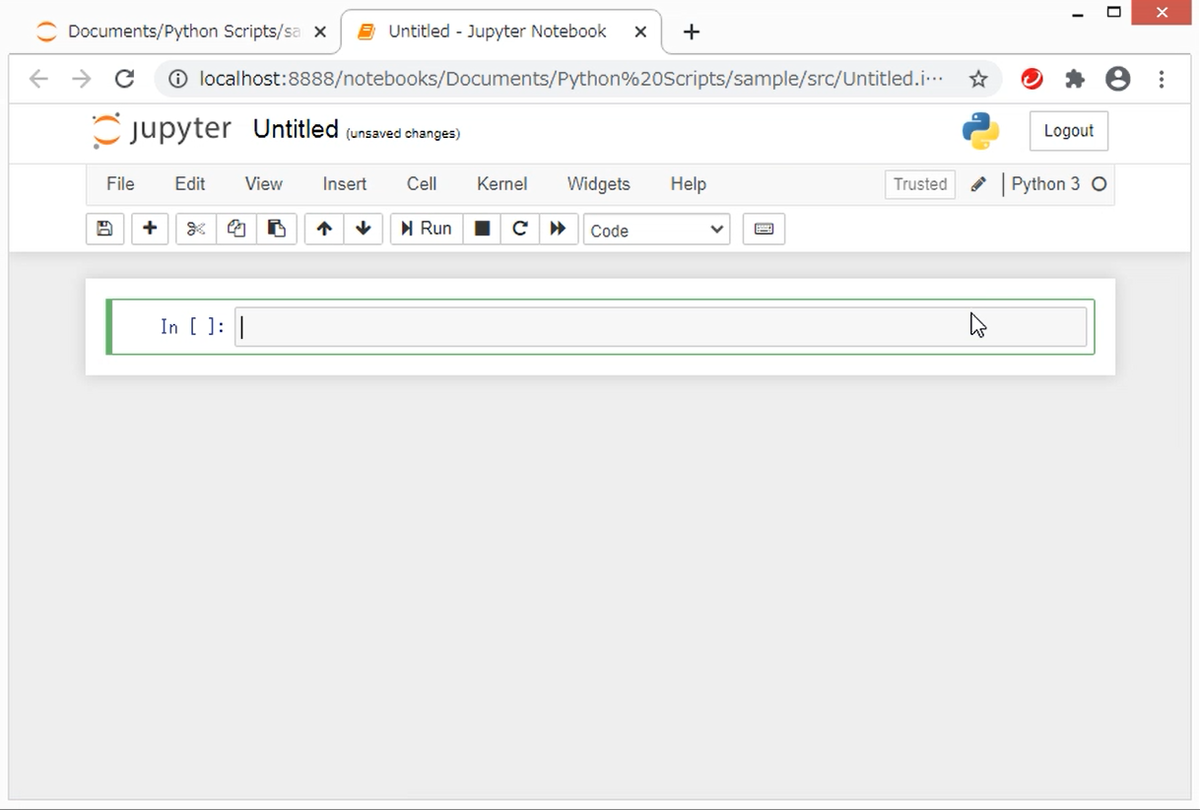
これで、ノートブックが作成できました。
なお、左上の「Untiltled」はノートブックの名前で、クリックすると名前を変えることができます。あとで、ノートブックを見つけやすいように、プログラムの内容を表す名前を付けるようにしましょう。
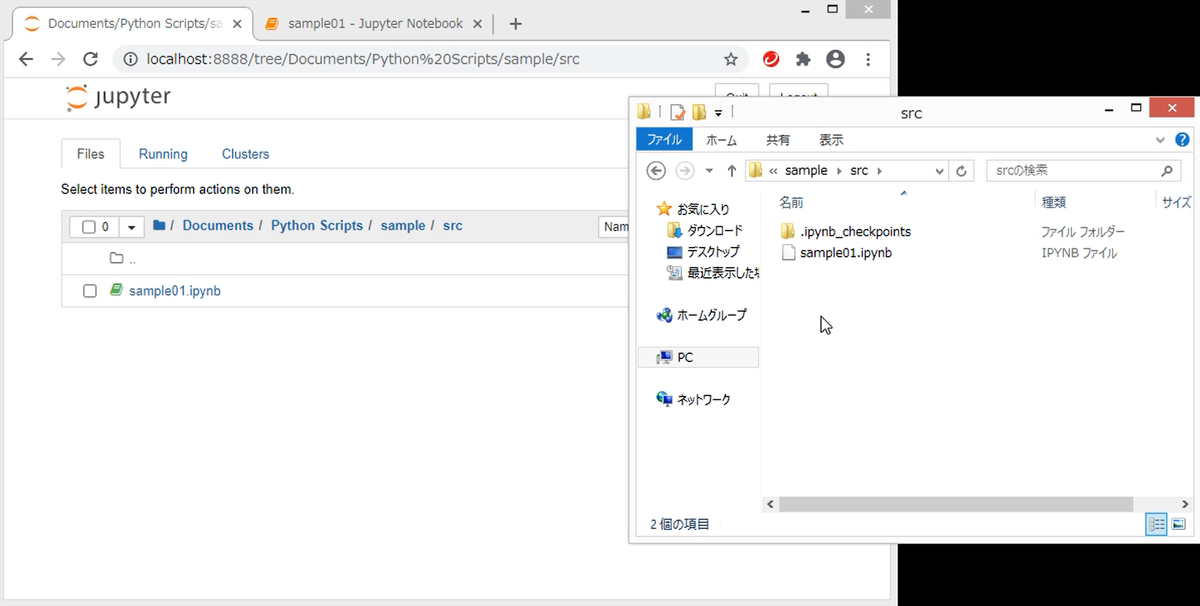
ノートブックは、ファイル名に「.ipynb」という拡張子が自動で付いて保存されます。ファイル名の拡張子が「.ipynb」なのは、以前、Jupyter Notebookは、IPython Notebookと呼ばれていた名残です。
プログラムの実行
実際にノートブックにプログラムを書いて実行してみましょう。
Jupyter Notebookでは、In[ ]:と表示されているセルにプログラムを記述することができ、セルの単位でプログラムを実行することができます。全体として長いプログラムを書く場合にも、例えば、'ファイルの読み込み'と'グラフの描画'を別々のセルを分けて書くことで、途中の結果にエラーや誤りがないことを確認しながら進めることができるため便利です。
プログラムを実行する時には、上にある[Run]ボタンを押します。または、キーボード操作で、[Shift]+[Enter]キーを押しても実行できます。慣れれば、[Shift]+[Enter]キーの方が速いです。
以下は、「print('Hello world!')」と書いて実行したイメージです。
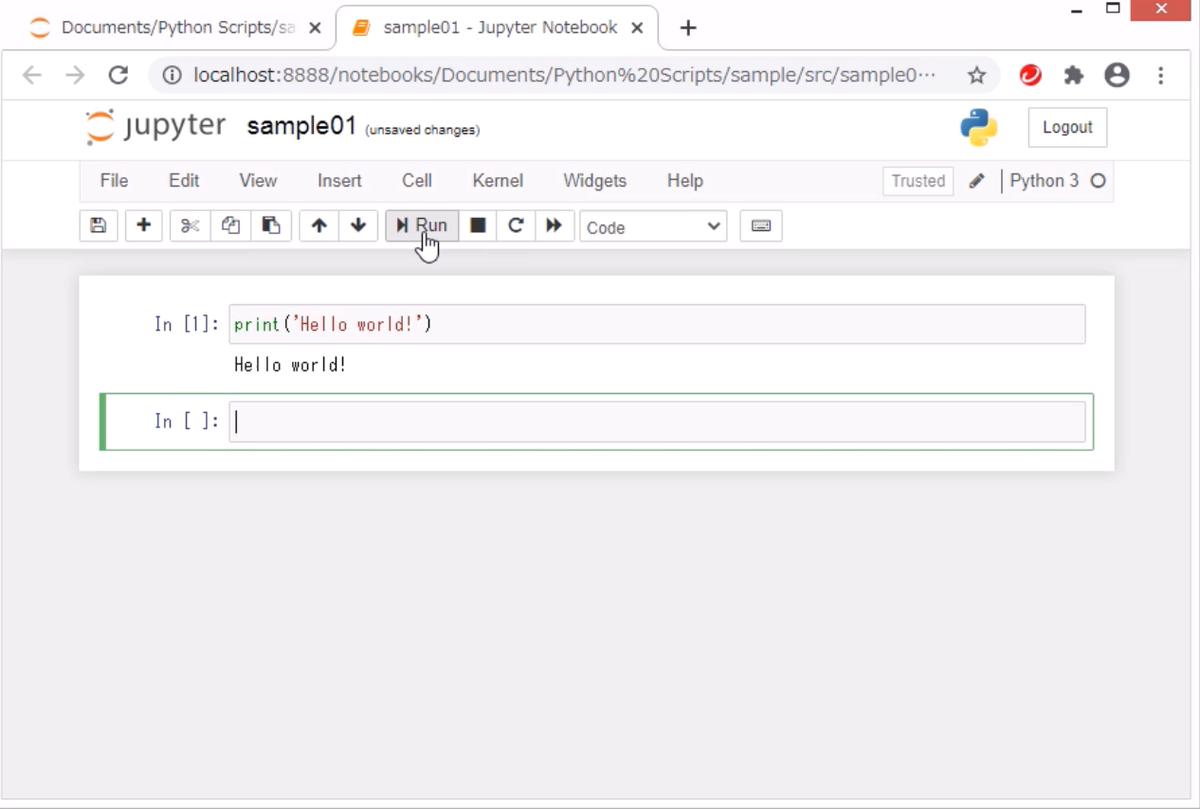
「Hello world!」という文字列が、実行結果として表示されています。このように、Jupyter Notebookでは、文字列・表・グラフなど、プログラムを実行した結果として表示するものがある場合は、実行したセルの下に表示されます。
その他の基本操作
プログラムを実行するボタンの他にも、いくつかのボタンが用意されています。それらのボタンを押すことで、Jupyter Notebookにおける基本的な操作を行うことができます。それぞれのボタンと対応する操作は、以下のとおりです。
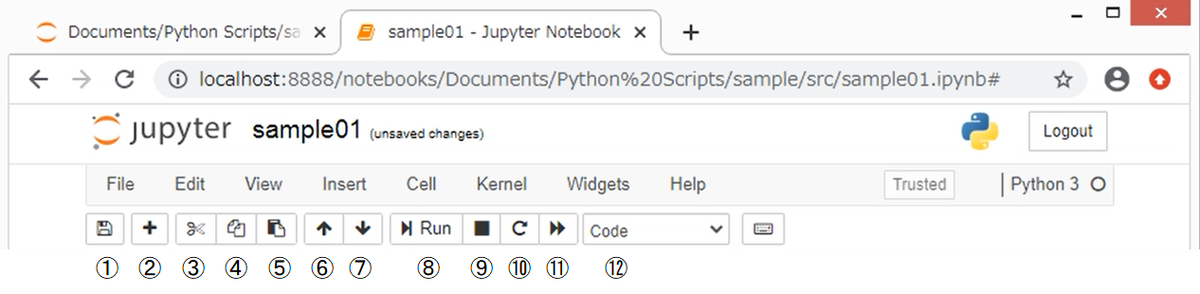
①ノートブックを保存する
②セルを追加する
③選択したセルを切り取る/削除する
④選択したセルをコピーする
⑤切り取りまたはコピーしたセルを貼り付ける
⑥選択したセルを上方向に移動する
⑦選択したセルを下方向に移動する
⑧選択したセルを実行する
⑨実行中のプログラムを停止する
⑩ノートブックを再起動する
⑪ノートブックを再起動して、全体を上から順に実行する
⑫入力モードを変更する
特に知っておくと役に立つ機能として、③~⑦の操作は、実行結果の部分も含めてコピーや並べ替えができます。そのため、分析作業の試行錯誤をした後で、プロセスを整理する際にとても便利です。

また、⑫の入力モードについては、次のセクションで紹介します。
説明文の記述
Jupyter Notebookでは、プログラムの説明文をMarkdownで記述することができます。ここでは、その方法を紹介します。
それぞれのセルは、デフォルトではCodeモードになっていて、プログラムを実行できる状態になっています。これをツールバーの右上にあるプルダウンメニュー(前セクションの図の⑫)から、「Markdown」を選択することで、Markdownモードに変更して、テキストを入力できる状態になります。説明文は、Markdownモードにして記述します。なお、キーボード操作で、[Esc]+[M]キーを押してもMarkdownモードに切り替えられます。
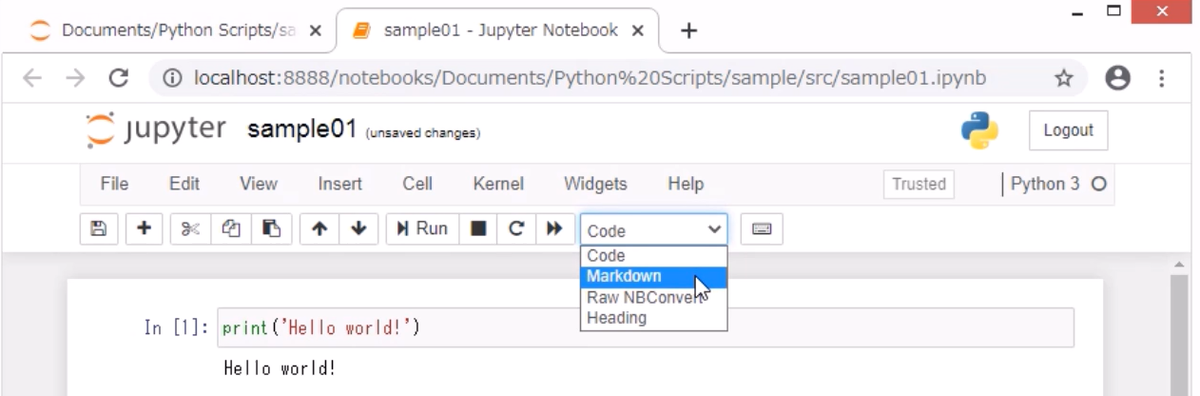
Markdownは、文章を見栄えの良いスタイルで記述するための記法(マークアップ言語)の1つです。Markdownを使って文章を書くと、見出しや強調などの文字装飾が簡単にできます。Markdownの文法はたくさんありますが、Jupyter Notebookでデータ分析の作業を整理する用途で使用する場合、まずは、見出しが使えれば十分だと思います。本記事の冒頭に貼ったイメージのように、見出しを使ってそのプログラムが何をやっているか説明する文章を入れると、あとから見返したときに理解しやすいです。

Markdownで見出しは半角シャープ(#)を使います。シャープの数によって、見出しの大きさを変えることができます。また、シャープと見出し文字の間には半角スペースを1つ入れる必要があります。
説明文を記述し終えたら、Markdownモードのセルを選択した状態で、実行ボタンを押す、または[Shift]+[Enter]キーを押します。すると、以下のように表示が切り替わります。

Markdownモードで表示を切り替えた後は、セルの枠が消えます。プログラムのセルの外側に説明文が記述された状態になるため、視覚的に見やすく整理できることがJupyter Notebookの特徴です。
まとめ
Jupyter Notebookの使い方について紹介しました。他にも便利な機能がありますので、実際に使ってみて色々と試してみていただきたいと思います。Jupyter Notebookは、データサイエンティストにとって必須ともいえるツールですので、これからデータサイエンティストを目指す方にとって、この記事が少しでもお役に立てば幸いです。
また、本記事で紹介した内容を動画にして、アップロードしています。よければ、こちらも併せてご参照ください。
youtu.be
最後まで読んでいただき、ありがとうございました。
データサイエンティストを目指す方向け Pythonセットアップ方法(Windows版)
2021年は自分から発信をしていこうということで、ブログを始めることにしました。IT企業にて10年以上勤務してきた中で培った経験を基に、技術的なトピックについて共有していこうと思います。
第1回目は、Pythonのセットアップ方法を紹介します。Pythonは、近年、人気のプログラミング言語です。シンプルな文法でプログラムを書けることや、ビッグデータを処理するための便利な機能が豊富に用意されていることなどが、人気の理由として挙げられます。私自身、データサイエンティストとして働く中で、Pythonは欠かせない存在だと感じています。
今回の記事では、簡単ではありますがセットアップ方法をまとめました。これからデータサイエンティストを目指す方、Pythonを始める方の参考になれば幸いです。
1. Anacondaのダウンロード
Anacondaとは
Anacondaは、Pythonのディストリビューション(Pythonおよび、関連ソフトウェアの集まり)です。データ分析向けのライブラリやツールが多く含まれていて、それらをまとめてインストールすることができます。入手するにあたって、本記事の執筆時点では、会員登録等の手続も不要で、どなたでも無料で使うことができます。また、インストール手順も、とても簡単です。そのため、Pythonのインストール方法はいくつかありますが、今回紹介するAnacondaを使った方法がデータサイエンティストをこれから目指す方にオススメです。
ダウンロード方法
「python anaconda download」と検索して、「anaconda.com」という公式サイトのURLが付いたリンクを選択します。
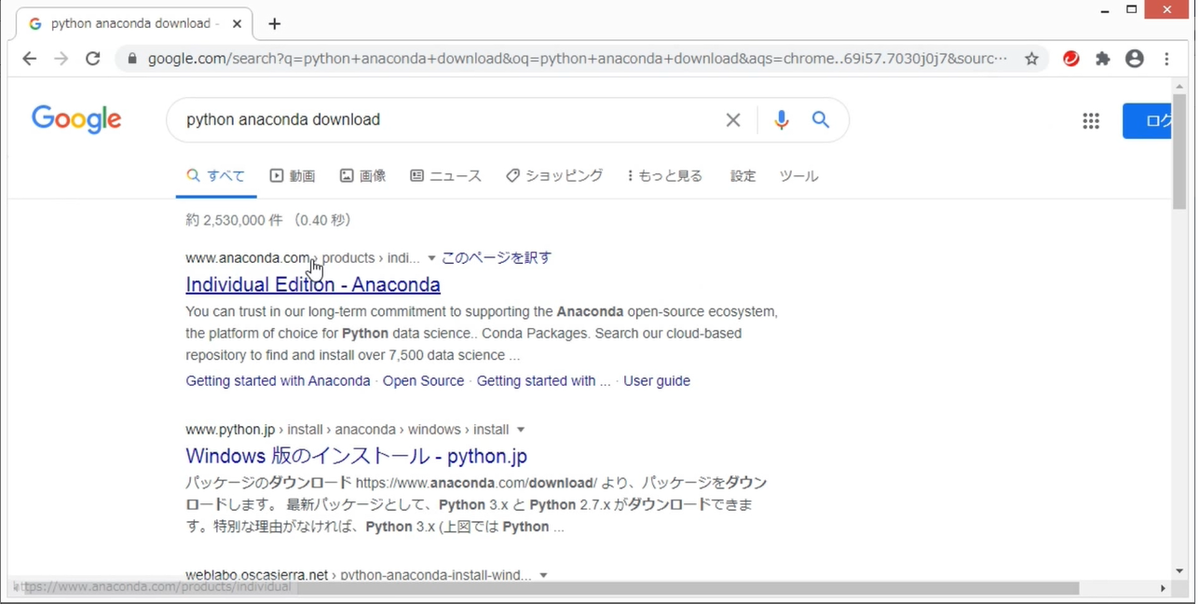
もしくは、以下のリンクからも公式サイトに行けます。こちらは、URLが変わるかもしれないため、ご注意ください。
ページの中からインストーラを探して、自身のマシン環境に適したインストーラを選択します。すると、ダウンロードが始まります。
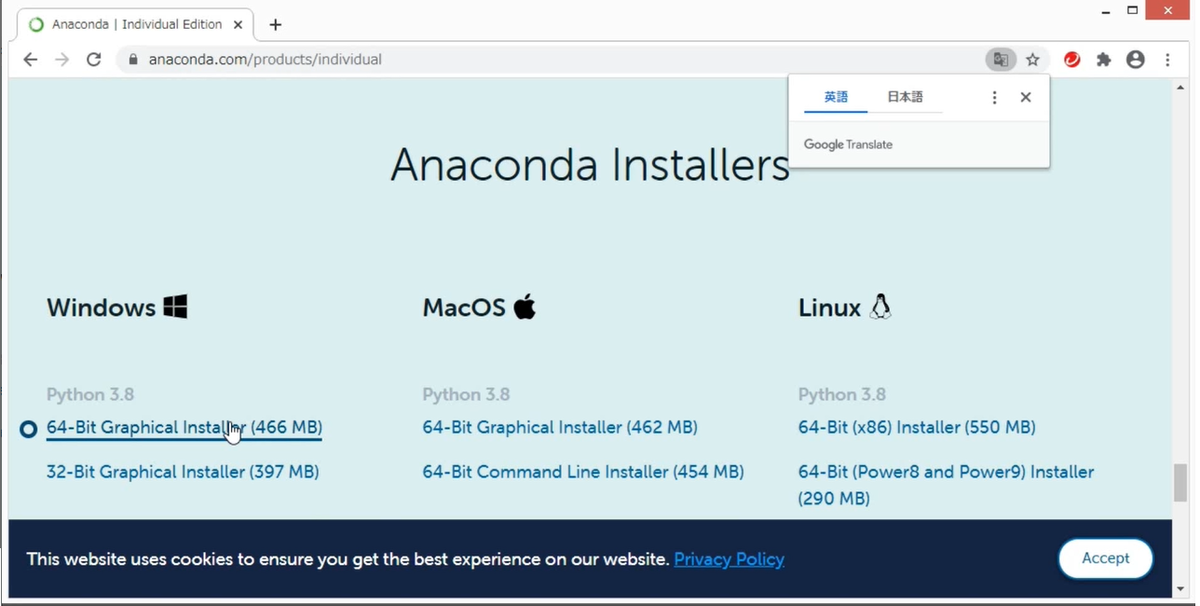
なお、ページのレイアウトは頻繁に変わりますので、こちらの画像は、あくまでも参考です。
2. Anacondaのインストール
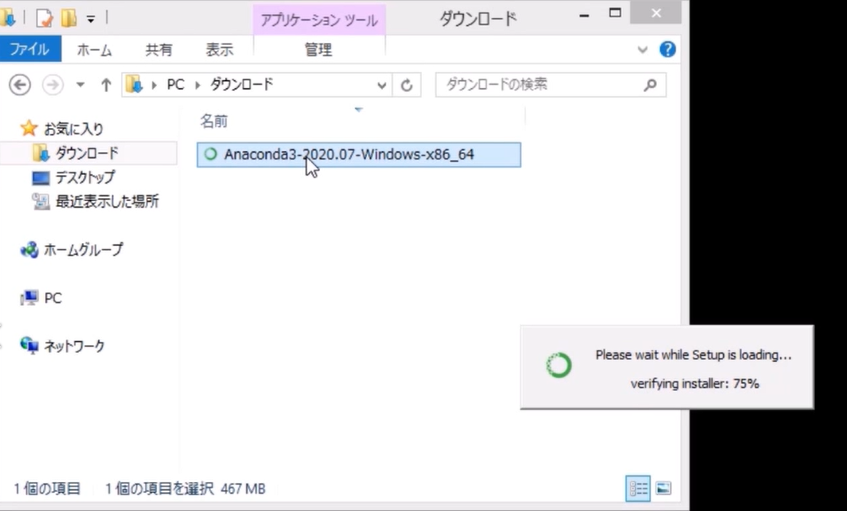
インストーラの起動
ダウンロード済のインストーラを起動します。ダウンロードフォルダなどに「Anaconda3-20XX.XX-Windows-x86_64.exe」があると思いますので、クリックまたはダブルクリックをして起動します。
インストーラを起動すると以下のような画面が表示されます。
インストール開始前の設定選択
インストールが始まる前に、いくつかの設定を選択します。基本的には、デフォルトの設定で「Next」を選んでいきますが、一か所だけ、デフォルトの設定からの変更した方が良い箇所があります。「Add Anaconda3 to my PATH environment variable」という項目に、デフォルトではチェックが入っていないと思いますが、チェックを入れることをオススメします。
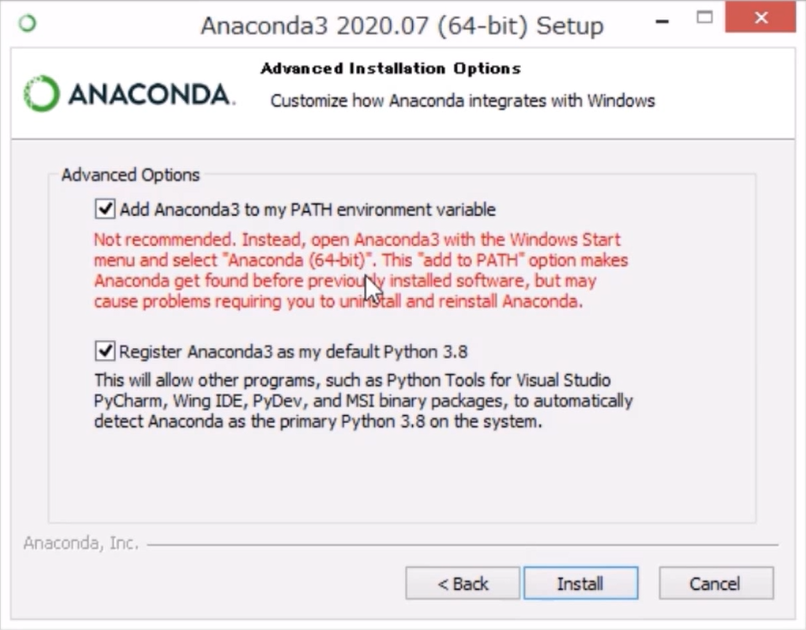
環境変数PATHについては、以降のセクションで紹介します。既にPythonの古いバージョンがインストールされていている場合に、この設定にチェックを入れると、既存のPythonの動作に影響が生じる可能性があります。Pythonを使ったシステム・サービスの動作に不具合が発生しないように、安全のため、デフォルトではチェックを外しているのだと思います。
上記の画面で、「Install」をクリックするとインストールが始まります。
インストール完了後
「Completed」と表示されたら、インストールは完了です。
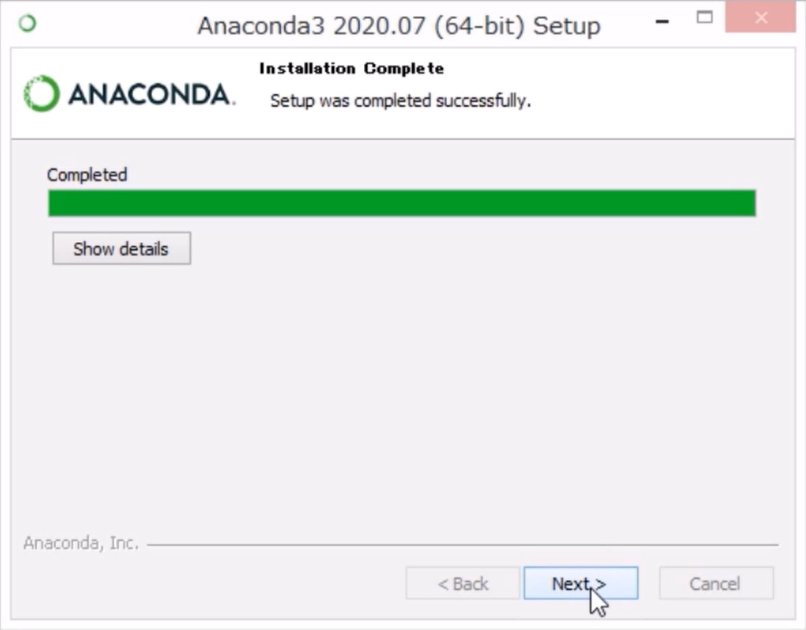
「Next」をクリックします。次の画面も「Next」をクリックします。以下の画面が最後です。
インストーラを終了した後に、Anacondaのチュートリアルページにアクセスするかの確認です。不要の場合は、チェックを外します。ここで、「Finish」をクリックすると、インストール作業の完了です。
3. 環境変数の確認
環境変数とは
環境変数とは、OS(Windows、Linuxなど)側で保持している変数のことです。その中の1つに「PATH」という変数があります。通常、PATHには、ソフトウェアの起動ファイルの格納フォルダを設定します。これにより、PATHを設定済のソフトウェアは、その起動ファイルの場所を指定しなくても、システム側でPATHに設定されたフォルダ内を自動的に探してくれるようになります。そのため、ソフトウェアの起動が簡単になります。
ここでは、まず、環境変数が正しく設定されていることを確認します。
PATHの値を確認
「コントロールパネル」>「システムとセキュリティ」>「システム」>「システムの詳細設定」と進み、「環境変数」をクリックします。
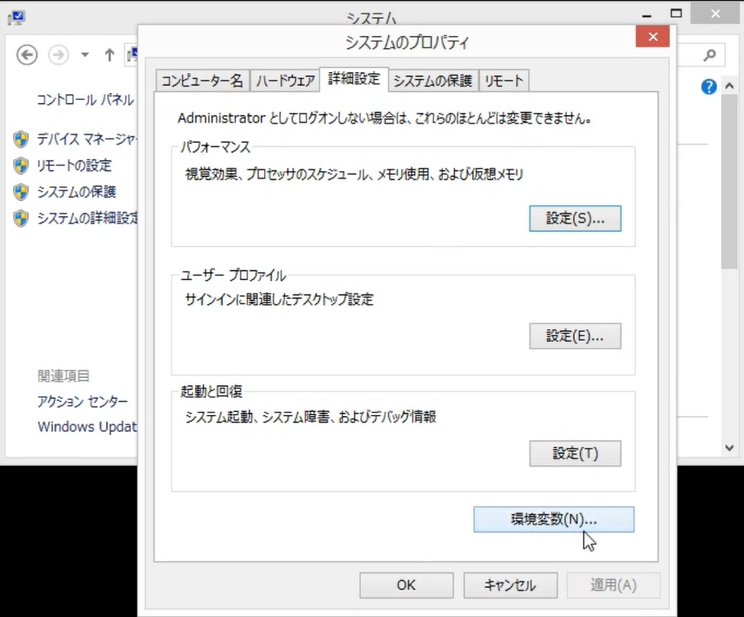
PATHの行を選択して、「編集」をクリックして値を確認します。
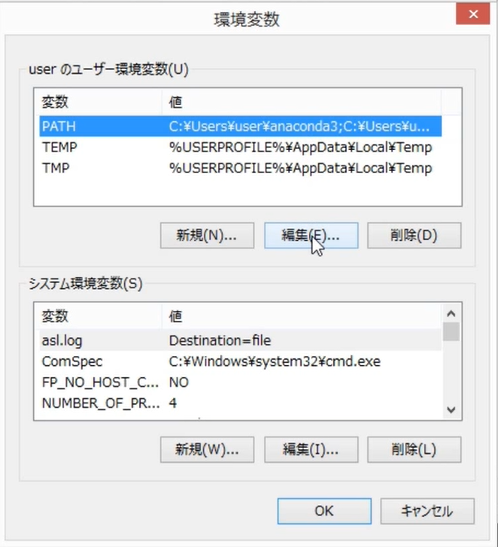
Windows10環境では、PATHに設定されている値が一覧表示されますが、Windows8環境では、複数の値がセミコロン(;)で区切られています。
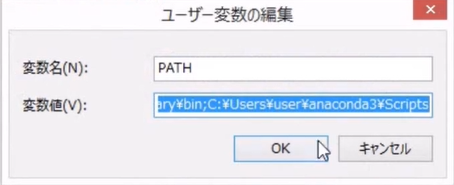
Windows8の場合は、コピーしてメモ帳に貼り付けると見やすいです。以下の5つの値が設定されていることを確認します。
- C:[インストールフォルダ]\Anaconda3
- C:[インストールフォルダ]\Anaconda3\Library\mingw-w64\bin
- C:[インストールフォルダ]\Anaconda3\Library\usr\bin
- C:[インストールフォルダ]\Anaconda3\Library\bin
- C:[インストールフォルダ]\Anaconda3\Scripts
Aancondaでインストールした、Pythonおよび関連ツールの起動ファイルは、これらのいずれかのフォルダに格納されているため、環境変数PATHの機能によって、どこからでも、それらのソフトウェアを実行できます。
4. Pythonの起動・動作確認
python.exeの実行
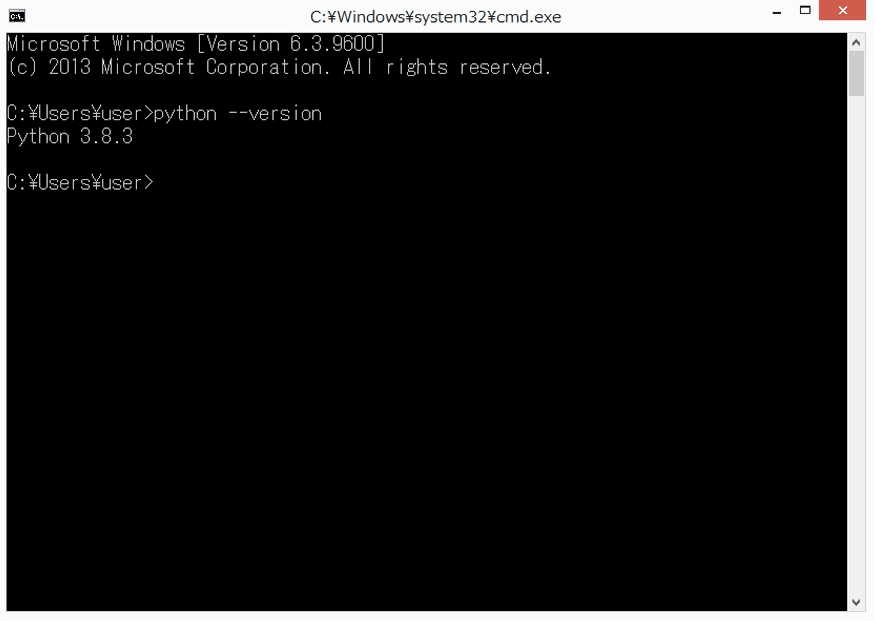
Windows版のPythonは、「python.exe」というファイルを実行することで起動できます。環境変数PATHに、Anacondaのフォルダを設定済であれば、ファイルの場所を指定しなくても起動できます。そのことを確認するため、今回は、コマンドプロンプトを使ってPythonを起動します。
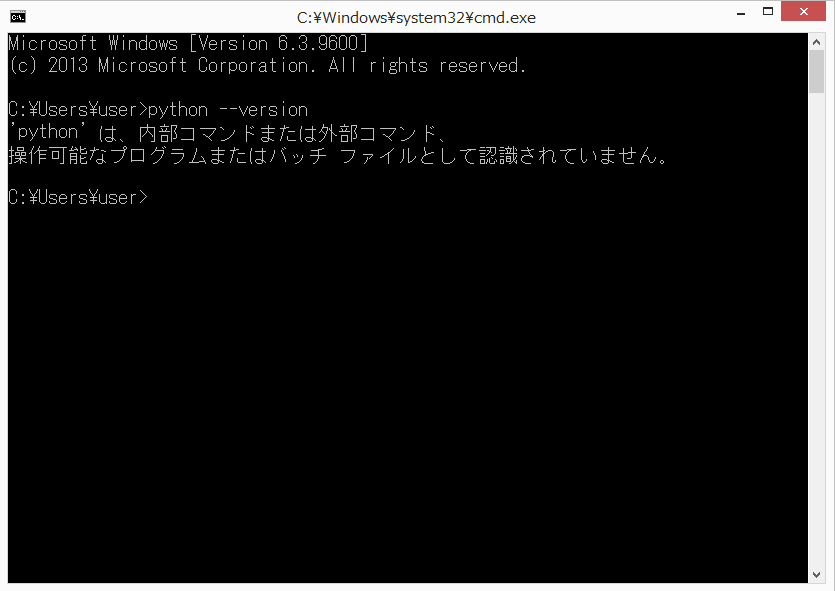
まず、コマンドプロンプトを開いて、「python --version」と実行します。以下の画面のように、バージョンが表示されれば、環境変数が正しく設定できています。
ちなみに、ここで実行した「python」コマンドは、「python.exe」の「.exe」を省略したものです。もし、環境変数が設定されていない場合、「python.exe」のファイルの場所がみつけられないため、以下のようなエラーになります。
次に、実際にPythonを起動します。「python」とだけ入力して[Enter]キーを押します。起動すると、以下のような画面が表示されます。
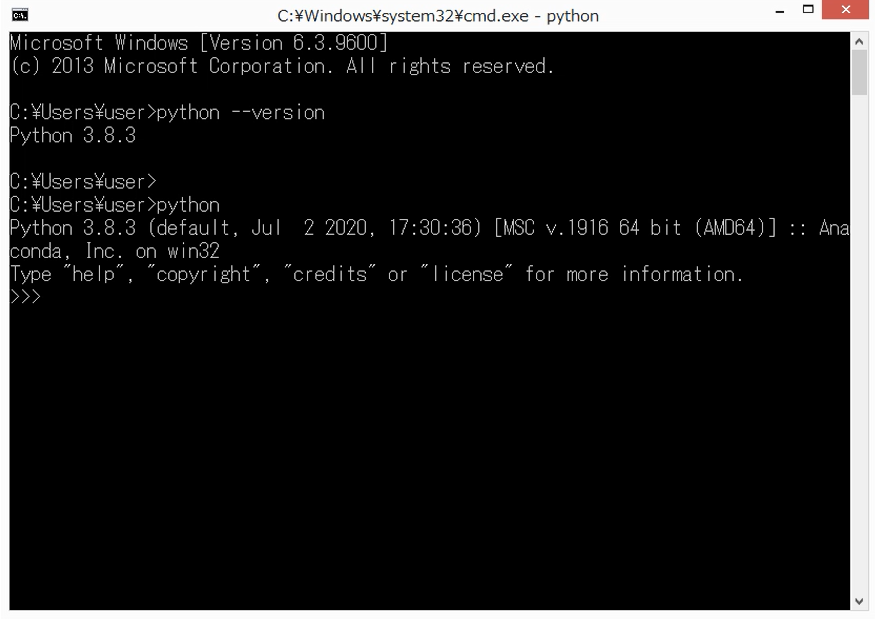
Pythonの動作確認
最後に、「Hello world!」というメッセージを表示するプログラムを書いて、実行・動作確認してみます。なお、「Hello world!」の表示は、多くのプログラミング言語で、最初に勉強するプログラムです。Pythonでは、このプログラムが1行で記述できます。「print('Hello world!')」と入力して、[Enter]キーを押して実行すると、「Hello world!」と表示されます。
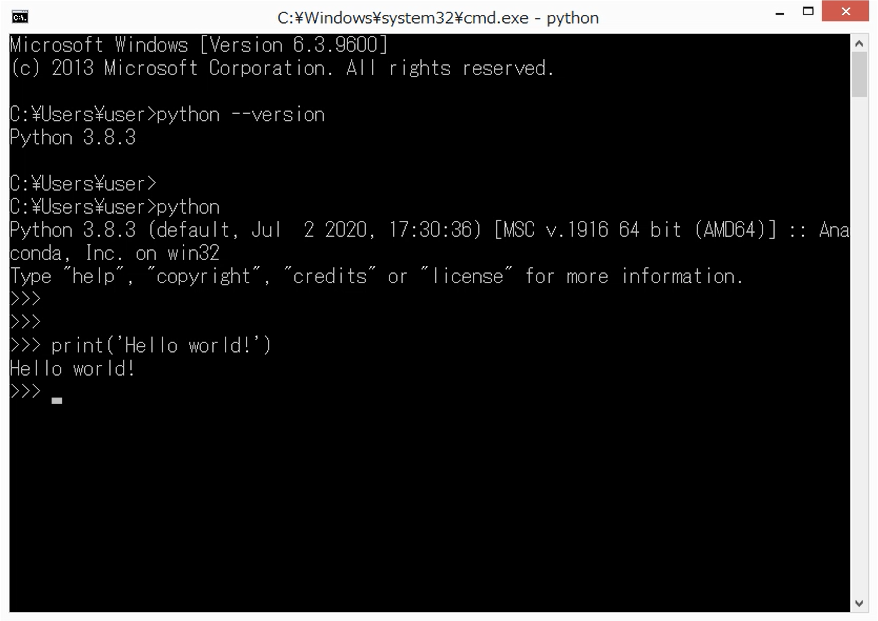
このように、Pythonでは、プログラムを簡潔に書けることが特徴となっています。なお、Java言語で同様のプログラムを書くと、書き方の作法にもよりますが、3~5行になります。
public class HelloWorld{ public static void main(String[] args){ System.out.println("Hello World!!"); } }
まとめ
Pythonのセットアップ方法についてまとめました。わかりづらい点もあったかと思いますが、少しでもお役に立てば幸いです。
また、全ての画面遷移をスクリーンショットして貼り付けるのが大変だったので、本記事で紹介したPythonセットアップの様子を動画にして、アップロードしています。よければ、こちらも参考にしてみてください。
最後まで読んでいただき、ありがとうございました。