データ分析者が知らないと損するLinuxコマンド5選
今回は、データ分析者にオススメのLinuxコマンドを5つ紹介したいと思います。

はじめに
Linux環境
Linuxはサーバー向けのOSですが、近年は、GCPやvirtualboxなどの仮想マシン上にLinuxをインストールして使っている方も多いと思います。その中でも、簡単にLinuxを使う方法の1つとして、前回の記事で紹介したCygwinをインストールする方法があります。Cygwinを使うとWindowsのPC上でLinuxコマンドを実行することができます。まだの方は、是非インストールしてみてください。
dskevin.hatenablog.com
コマンド実行用のサンプルデータ
それぞれのコマンドの実行例は、以下のサイトで公開されているオープンデータを使用しています。
Fire Department Calls for Service | DataSF | City and County of San Francisco
Fire_Department_Calls_for_Service.csv 約2GB
※米国サンフランシスコ市における、緊急車両の出動要請のログデータ
1. headコマンド ~データの中身を確認~
説明
大きいサイズのデータファイルをExcelで開こうとすると、開くのに時間がかかったり、場合によってはフリーズが発生します。
Linuxのheadコマンドを使うと、テキストファイルの先頭10行を素早く表示することができます。
CSVファイルにも適用することができるので、大きいサイズのデータファイルの中身をざっと確認したい時に便利です。
head ファイル名
headコマンドは、-nオプションを使用することで、表示する行数を指定することも出来ます。
head -n 行数 ファイル名
また、別のファイルに保存したい場合は、以下のように「> 出力ファイル名」を付けて実行します。
head ファイル名 > 出力ファイル名
このように、Linuxでは実行するコマンドの最後に「> 出力ファイル名」を付けると、出力結果を別のファイルに保存することができます。
実行例
サンプルデータを用いて、実際にコマンドを実行してみます。
まずは、ファイルを置いてあるディレクトリに移動します。今回は、デスクトップに置いてあります。ここで、「userpc」の部分はログインユーザ名に置き換えてください。
cd /cygdrive/c/Users/userpc/Desktop/
headコマンドを実行します。
head Fire_Department_Calls_for_Service.csv
実行イメージは以下のとおりです。
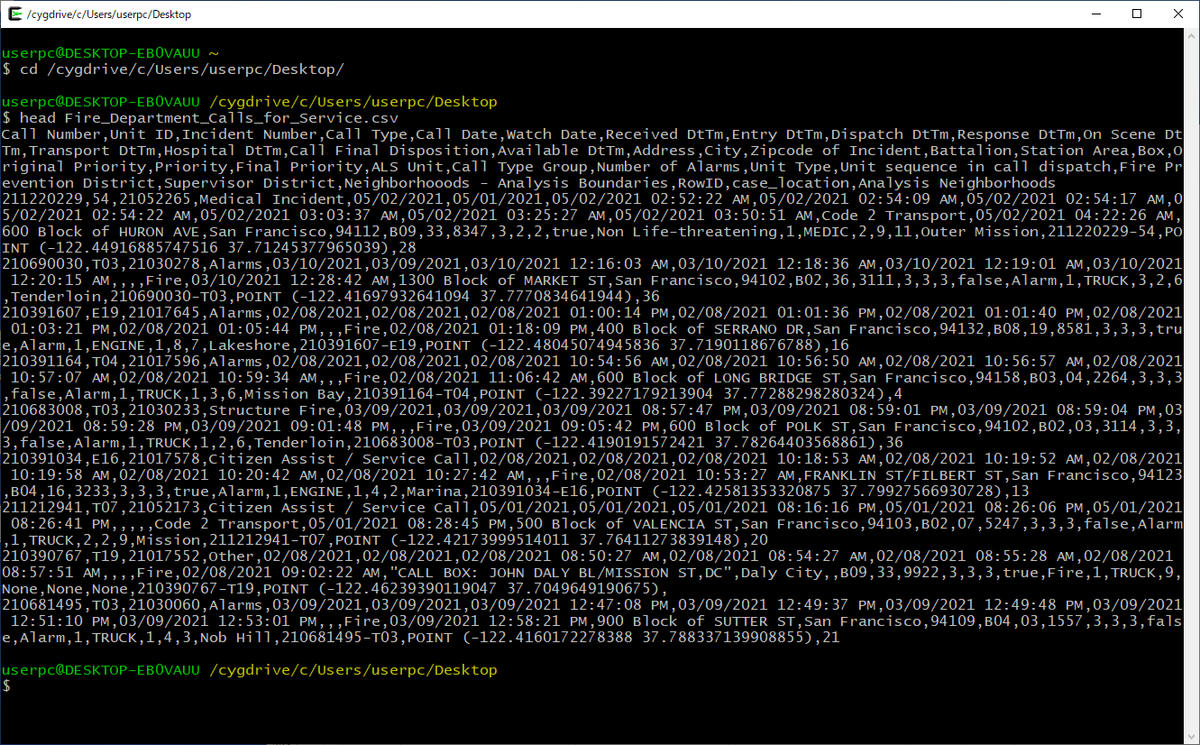
ファイルの冒頭部分が表示されました。このように、どのような内容が含まれているか確認することが出来ます。ただし、今回のデータは1行が長く、改行されていて見づらいのです。そこで、先頭20行を別のファイルに保存してExcelで開いてみます。
head -n 20 Fire_Department_Calls_for_Service.csv > tmp_data.csv
tmp_data.csvが同じディレクトリに生成されるので、Excelで開いてみます。こちらは、ファイルのサイズが小さくなっているため、すぐに開けました。
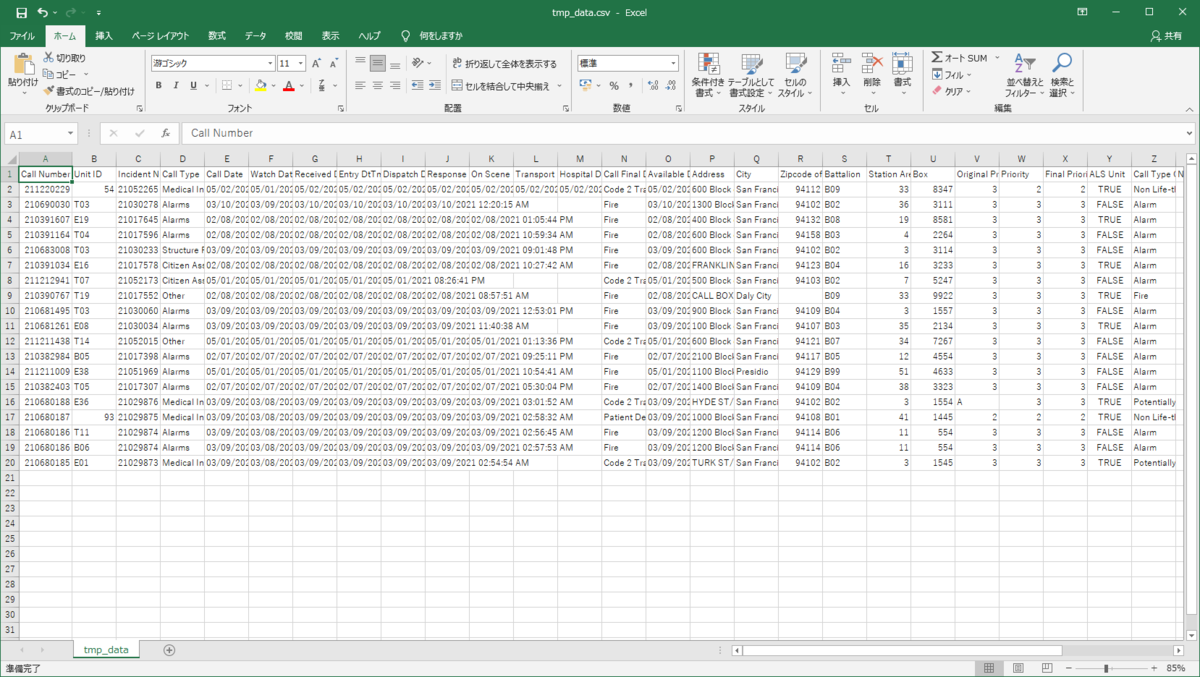
このように、大きいサイズのデータの中身を確認したい時は、headコマンドを使うと時間を短縮することができます。
2. grepコマンド ~特定の行を抽出~
説明
grepコマンドも大きいサイズのファイルを扱う際に便利なLinuxコマンドです。
grepコマンドを使うと、指定した文字列を含む行だけを表示することができます。データ分析において、データファイルの中から、分析対象のデータを部分的に抽出するときに役に立ちます。
grep "キーワード" ファイル名
キーワードはシングルクォーテーションまたはダブルクォーテーションで囲みます。
複数のキーワードを含む行を抽出したい場合は、「|」を使って、再度grepコマンドを書きます。2つ目以降はファイル名は不要です。
grep "キーワード1" ファイル名 | grep "キーワード2" | grep "キーワード3" ...
実行例
Fire_Department_Calls_for_Service.csvの中から、"04/12/2021"と"Explosion"を含む行だけを抽出する場合は、以下のように実行します。
grep "04/12/2021" Fire_Department_Calls_for_Service.csv | grep "Explosion"
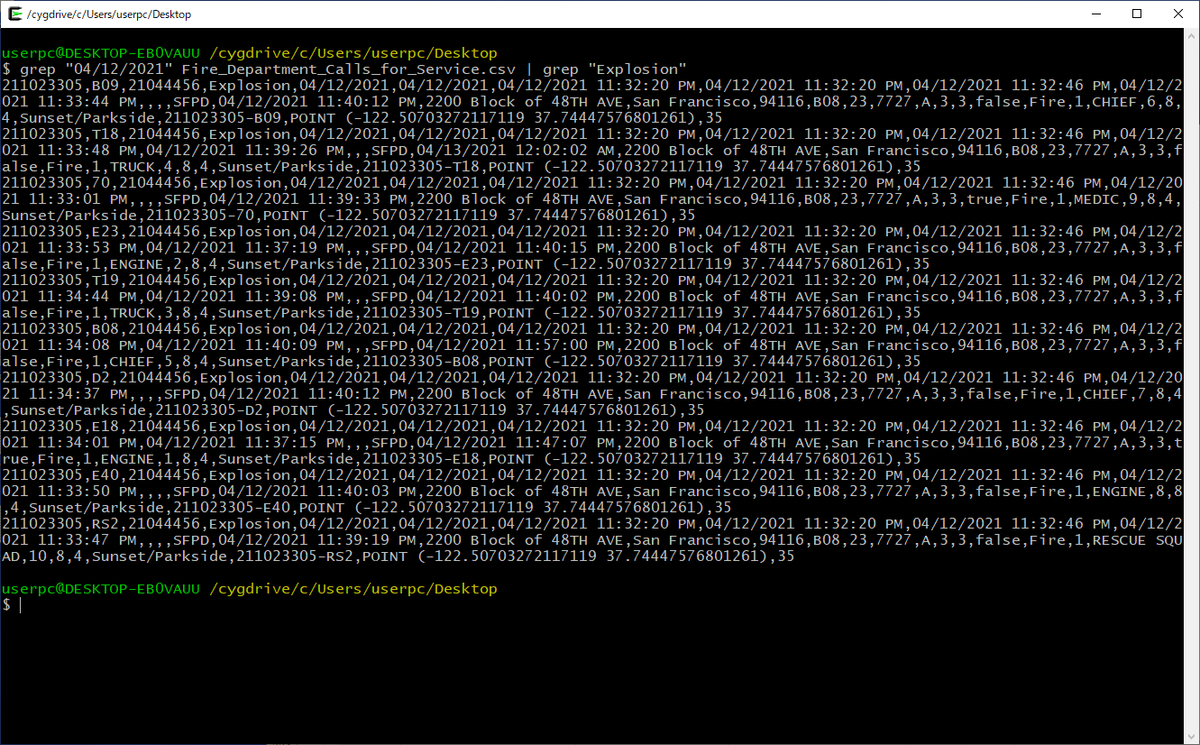
抽出した結果を別のファイルに出力する場合の実行例は、以下のとおりです。
grep "04/12/2021" Fire_Department_Calls_for_Service.csv | grep "Explosion" > explosion_20210412.csv
これで、2021年4月12日に対応したExplosion(爆発)による出動要請に関するレコードだけを抽出することができました。
3. cutコマンド ~特定の列を抽出~
説明
cutコマンドを使うと、CSVファイルの特定の列のみを抽出することができます。
分析に必要な列だけを残したいときに使用します。-f オプションに残したい列番号をカンマ区切りで複数指定できます。
cut -d , -f 列番号1,列番号2,... ファイル名
実行例
先ほど出力したCSVファイル(explosion_20210412.csv)から、1列目(Call Number)、4列目(Call Type)、5列目(Received DtTm)、17列目(City)、26列目(Call Type Group)を抽出する場合は、次のコマンドを実行します。なお、「-d ,」はファイルの区切り文字(deliminator)を指定するためのオプションで、CSVファイルはカンマが区切り文字なので「,」を指定します。
cut -d , -f 1,4,7,17,26 explosion_20210412.csv
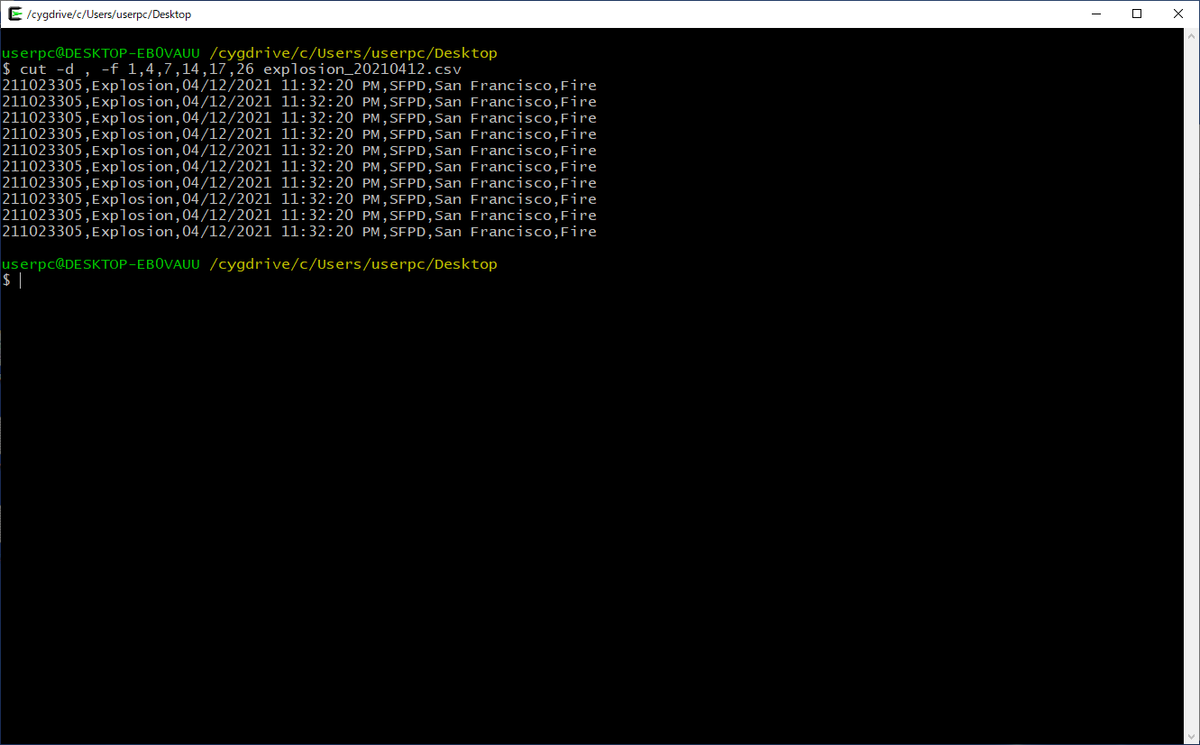
列が少なくなったため、改行が無くなり見やすくなりました。
ファイルに出力する場合は、以下のように実行します。
cut -d , -f 1,4,7,17,26 explosion_20210412.csv > explosion_20210412_v2.csv
4. uniqコマンド ~重複の除去~
説明
実務データにおいて、何らかの理由で同じデータが複数回記録されている場合があります。このようなデータを使用してデータ分析を行う際に、多くの場合、重複を取り除くことが適切です。
uniqコマンドを使うと、ファイルの重複行を取り除くことができます。ただし、uniqコマンドは連続する行が一致している場合にだけ重複を取り除くため、sortコマンドを使って全ての行をキャラクターコード順に並べ替えた後で、uniqコマンドを実行するのが一般的です。
sort ファイル名 | uniq
実行例
3.で実行したコマンド出力結果は全ての行が同じ内容でした。この結果に対して以下のコマンドを実行すると、重複を除くことができます。
sort explosion_20210412_v2.csv | uniq
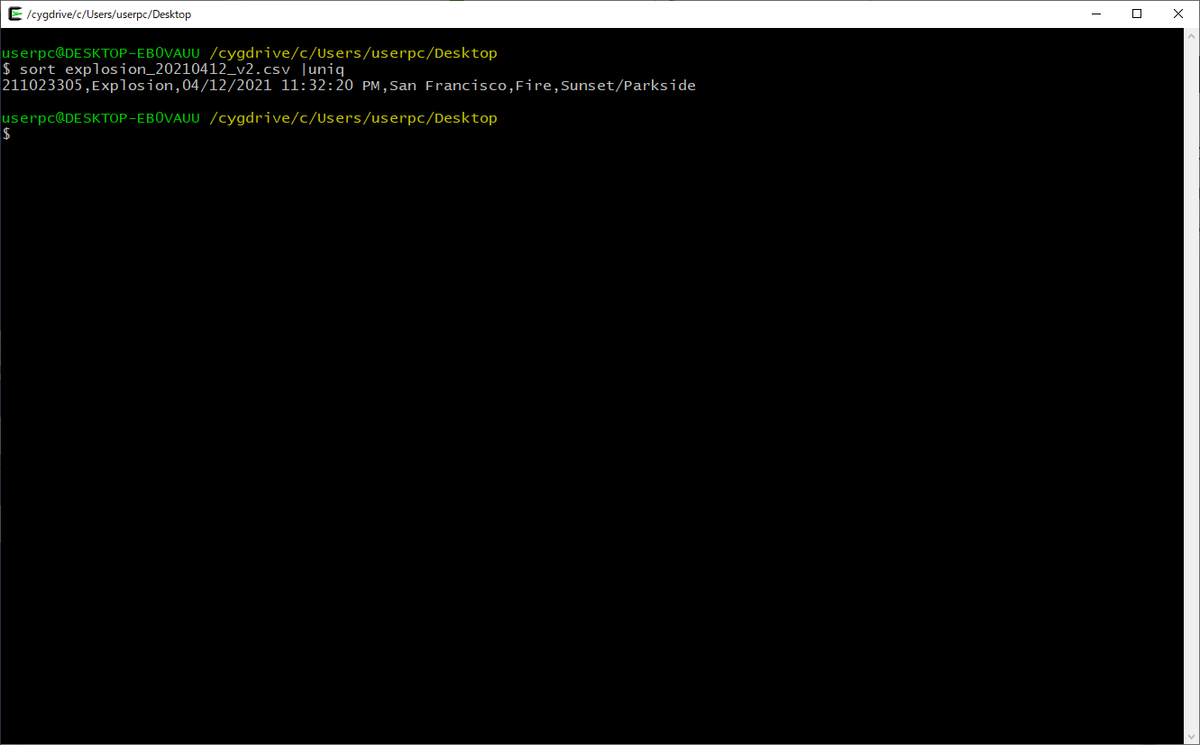
重複が除かれて、1行だけになりました。ちなみに、この場合は、全ての行が同じ内容だったので、sortをしなくても結果は同じですが、sortとuniqはセットで使うように覚えた方がよいです。
5. sedコマンド ~文字列の置換~
説明
データ分析時のデータの前処理として、文字列の表記ゆれを統一したり、文字列をデータを数値に変換するなど、文字列の置換をすることがよくあります。Excelでも以下のイメージのように、データ内の文字列の置換はできます。
しかし、大きいサイズのデータを扱う場合や、複数の置換パターンがある場合は、Linuxコマンドを使う方が速くて便利です。
sedコマンドを使うと、ファイルの中の特定の文字列を、別の文字列に書き換えることが出来ます。
sed -e 's/返還前の文字列/変換後の文字列/g' ファイル名
複数の置換パターンがある場合は、「|」でつなげて記述します。
sed -e 's/返還前の文字列1/変換後の文字列1/g' ファイル名 | sed -e 's/返還前の文字列2/変換後の文字列2/g'
応用
最後に、今回紹介したコマンドを組み合わせて、以下のデータ処理を一気に行ってみたいと思います。
・対象レコードは、2021年の全種類の出動要請
・対象カラムは、Call Number、Call Type、Received DtTm、City、Call Type Group
・重複は取り除く
・「San Francisco」を「SFO」に書き換える
すでに少し触れていますが、Linuxコマンドは「|」を使うことで、複数の処理をつなげて実行することができます。途中の出力結果を確認する必要がない場合は、「|」を使って一気に実行することで、更に効率化することができます。
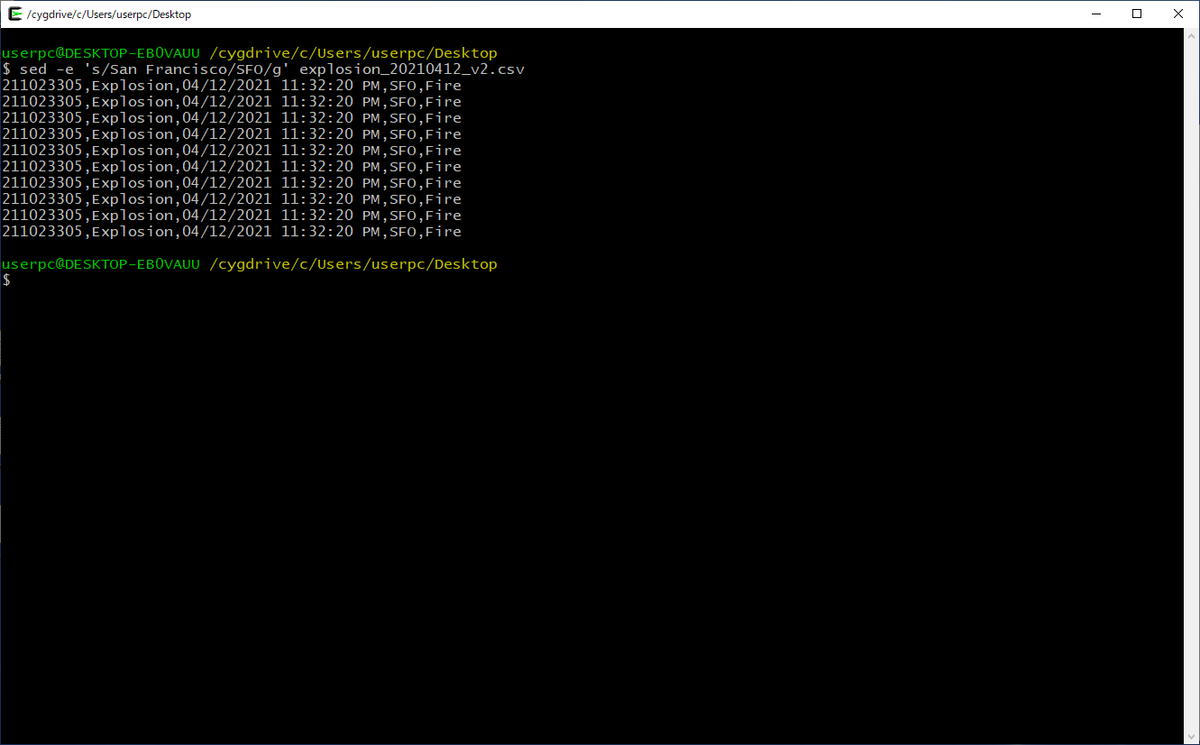
grep '/2021,' Fire_Department_Calls_for_Service.csv | cut -d , -f 1,4,7,17,26 | sort | uniq | sed -e 's/San Francisco/SFO/g' > sample_data_2021.csv
PCのスペックにもよりますが、数秒で終わると思います。
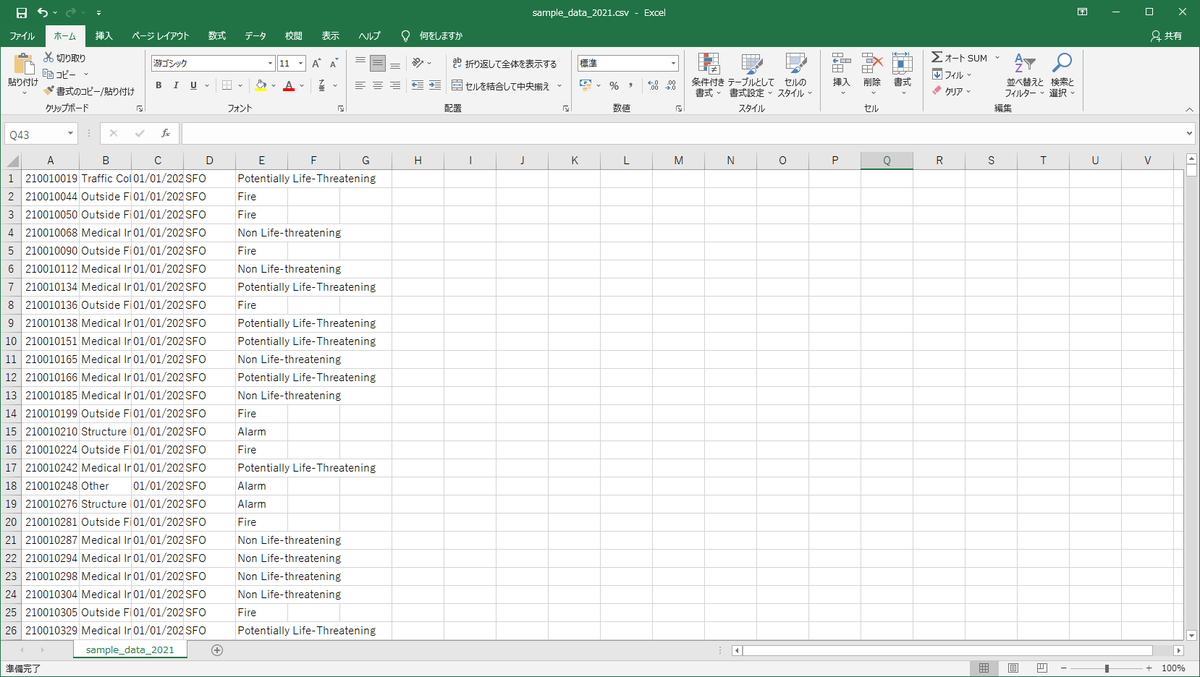
出力ファイルを開いたイメージはこちらです。もともと約2GBあったファイルサイズが約3MBまで小さくなっているので、すぐに開けました。
また、ヘッダーを付けたい場合は、以下の様に、まずheadコマンドで1行だけ出力します。その後で、同様の加工処理を実行して、「>」ではなく「>>」を使って追記モードで出力することで、先に出力したヘッダーの後にデータ部分が出力されます。
head -n 1 Fire_Department_Calls_for_Service.csv | cut -d , -f 1,4,7,17,26 > sample_data_2021.csv grep '/2021,' Fire_Department_Calls_for_Service.csv | cut -d , -f 1,4,7,17,26 | sort | uniq | sed -e 's/San Francisco/SFO/g' >> sample_data_2021.csv
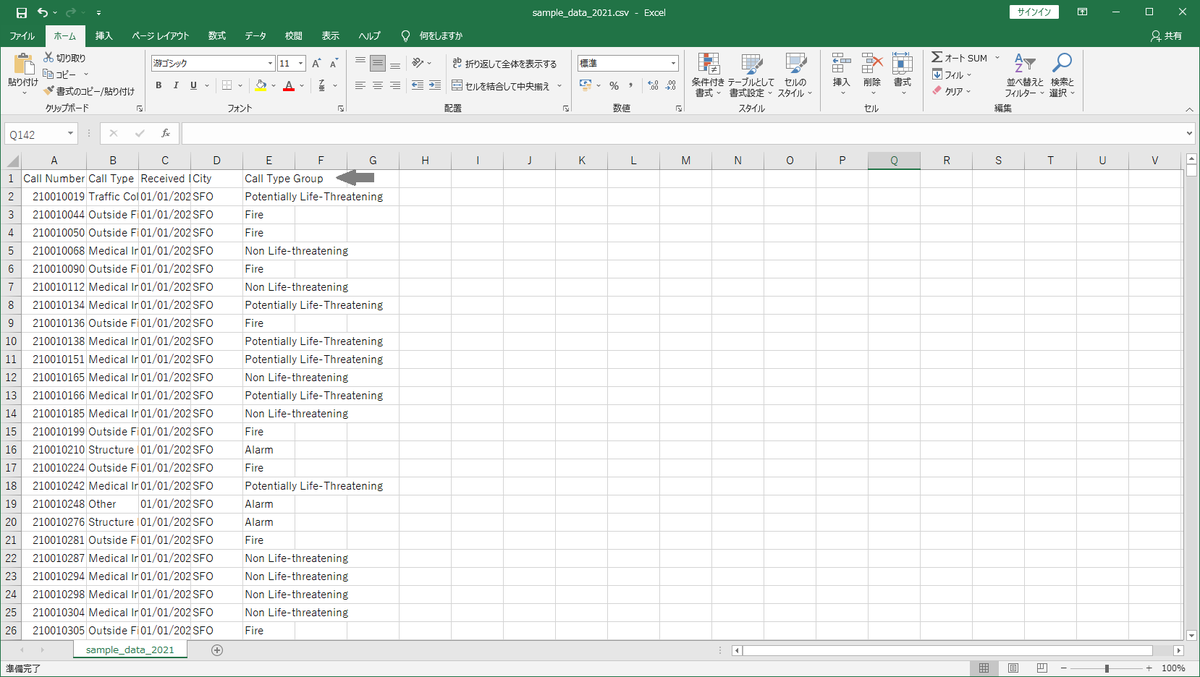
こちらも実行は数秒で終わると思います。
同様の処理をExcelやPythonなどのアプリケーションを利用して実行した場合に比べて、Linuxコマンドは圧倒的に速いです。(Linuxコマンド恐るべし!)